Summary
앞 단계의 evaluating을 통해 학습 부진이라고 판단된다면, 성능을 올려야 함.
앞 단계의 평가로 인해 가능한 대표적인 시나리오는 다음과 같음.
Check
transfer learning은 overfitting, underfitting 모두에 사용할 수 있다는 점.
Underfitting
Underfitting
Summary
모델이 더 이상 충분히 loss 를 줄이지 못함.
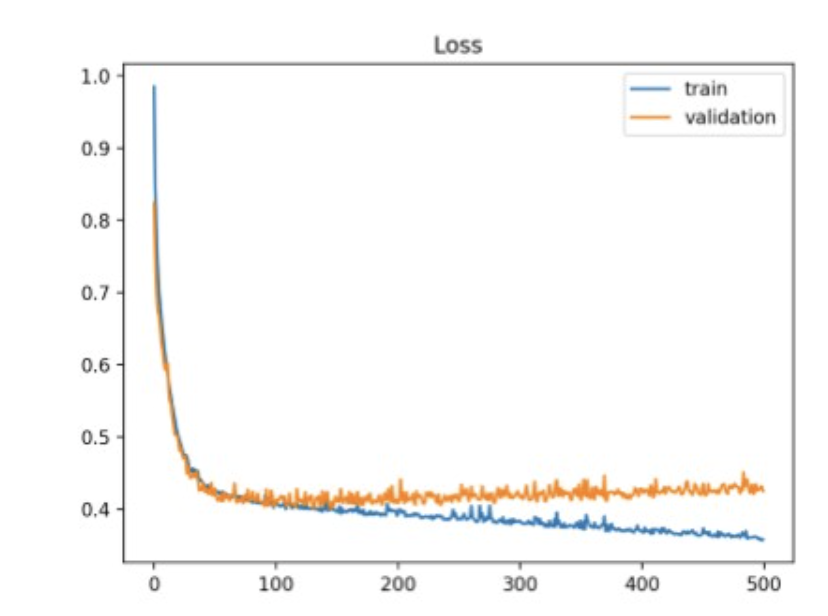
Training loss가 validation loss에 비해 낮음. → model의 capacity가 충분치 못함.Capacity vs Complexity
Capacity: 이론적으로 모델이 표현할 수 있는 function space의 크기
Complexity: 실제 학습된 모델의 표현력원본 링크Help
To solve the problem, several methods are recommended.
- Add more layer/units to model: model의 capacity의 부족으로 인한 문제를 직접적으로 해결.
- Tweak the learning rate : 기존에 잡힌 lr이 너무 커도 underfit이 되기도 하니, 줄여보고 판단.
lr이 초기에 너무 커버리면, 아예 학습이 진행되지 않은 경우가 될 수도 있어서 이게 underfit 개형으로 보이는 것.- train for longer: 더 해보면 될 수도?
- Transfer Learning: underfit의 요인 중 하나로 빈약한 representation을 꼽을 수 있고, 이는 이미 representation이 풍부한 pre-trained model에서 가져와서 수정하는 것으로 어느 정도 완화할 수 있음.
- use less regularization: regularization 즉, penalty를 너무 tight하게 잡아서 모델의 학습이 지지부진한 걸 수도. 이때에는 오히려 penalty를 완화시켜서 접근.
Overfitting
Overfitting
Summary
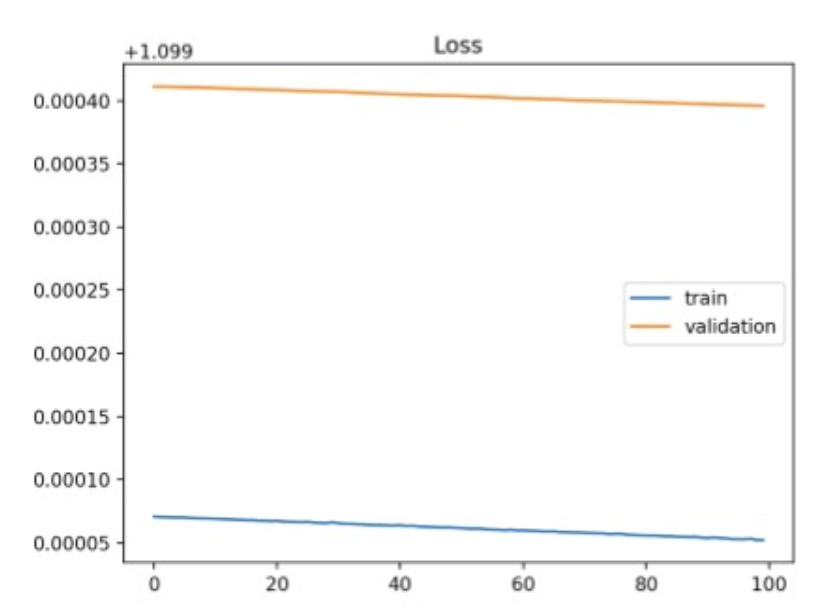
Training loss는 계속 줄지만, validation loss은 낮아지지 않음.
train을 계속하면, 모델은 train-set에만 잘 작동하는 함수로 fitting되니,
generalization이 떨어지고, validation-set 또는 unseen-data에 대해서도 loss가 커짐.원본 링크Help
To solve the problem, several methods are recommended.
- Get more data: 사실상 이게 best. 그러나 cost-issue.
모델한테 패턴을 학습할 기회를 더 주는 것.- Data Augmentation : 데이터를 더 collecting 하는 것 보단 현실적.
train-set의 diversity를 주는 것.- Better Data: low-quality data를 remove.
- Transfer Learning: task-suit 하게 준비된 set으로 fine-tune.
- Simplify model: 모델의 capacity가 충분해서 train-set의 너무 과한 패턴을 학습한 거니, 모델의 복잡성을 줄여서 generalization performance 확보.
- Learning Rate decay: fine-tune은 학습 후반에서 미세한 gradient에서 학습하는 거니, decaying은 후반에서 이러한 것들을 완화해줌.
- Early Stopping: overfit 되기 전에 stop.