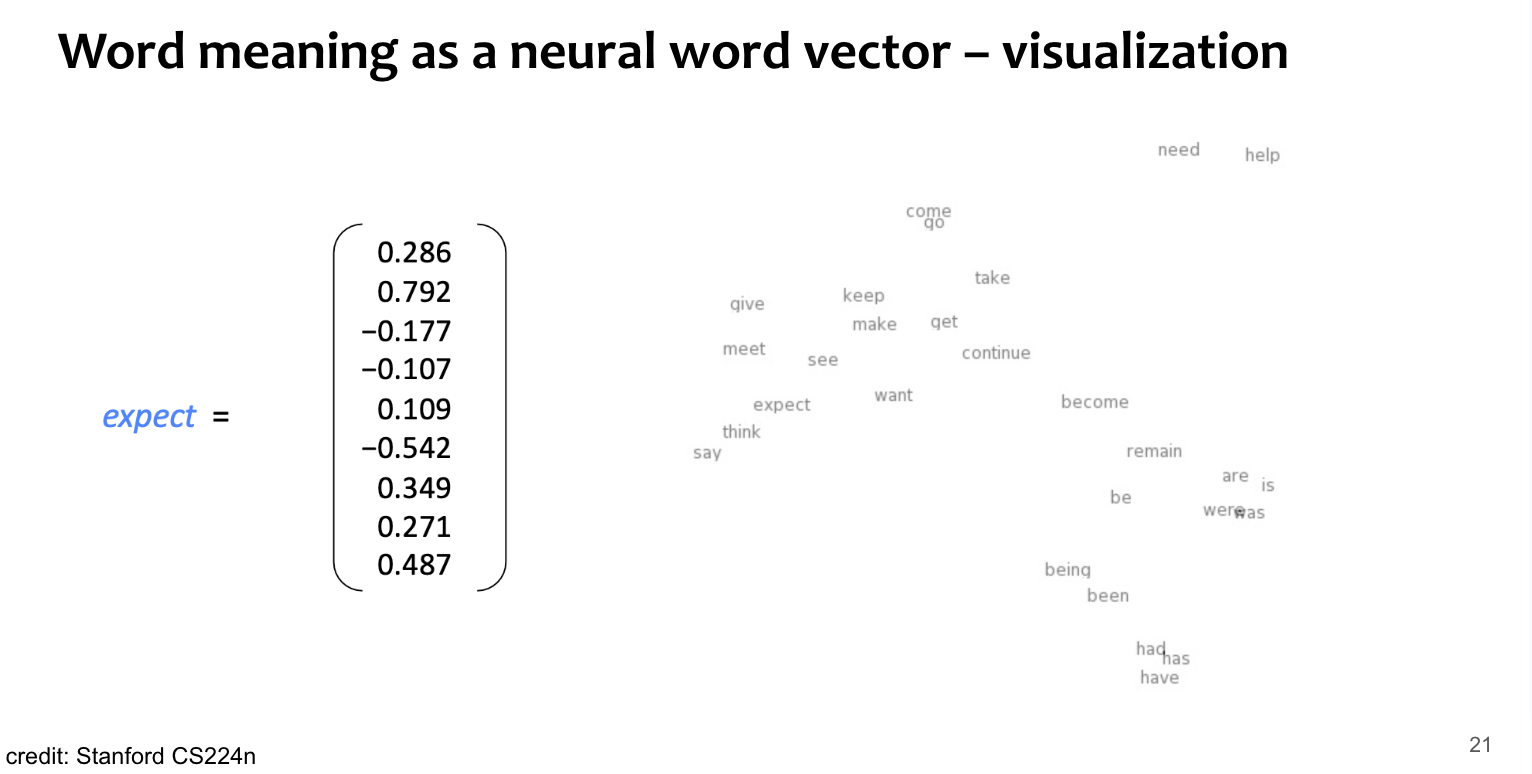
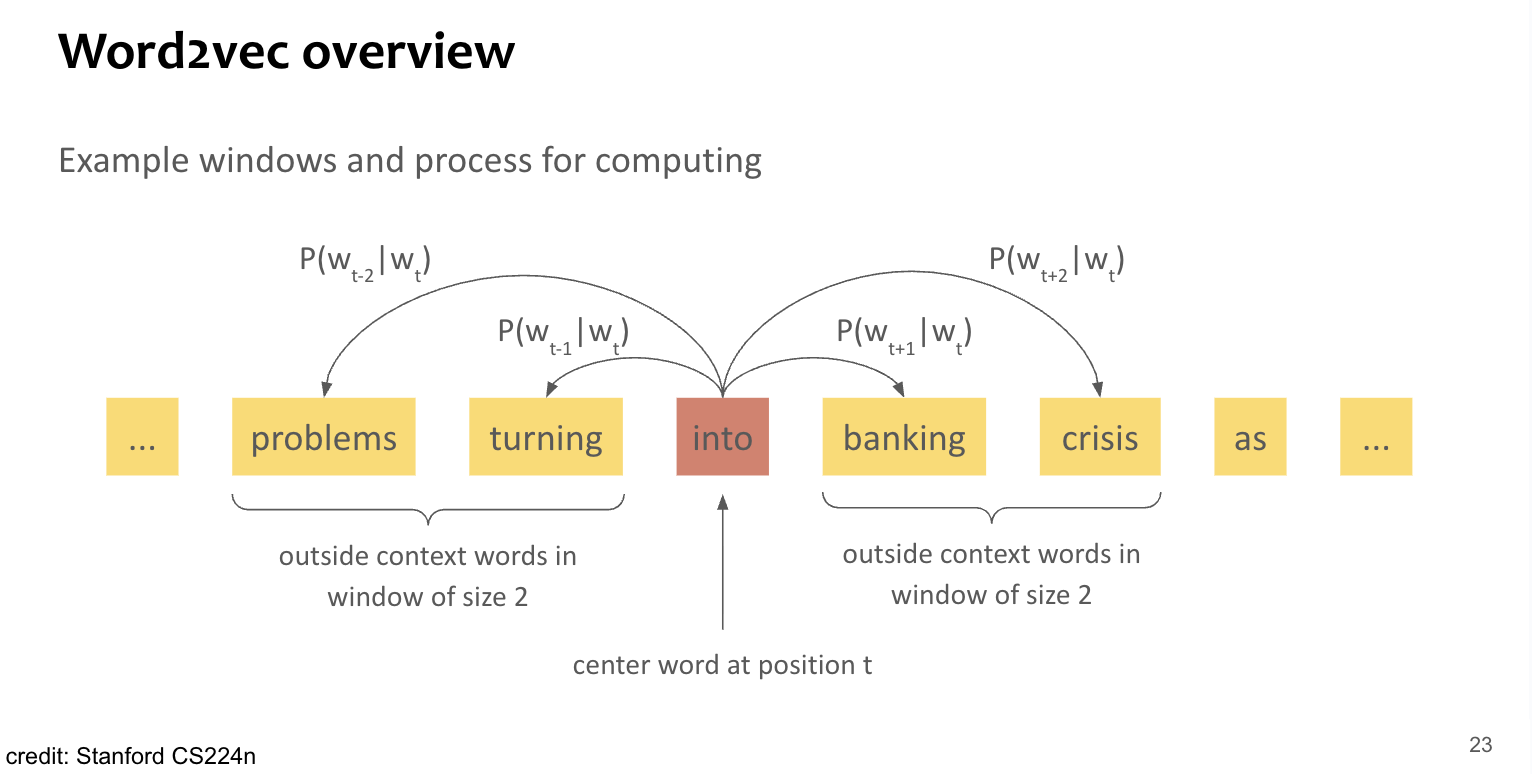
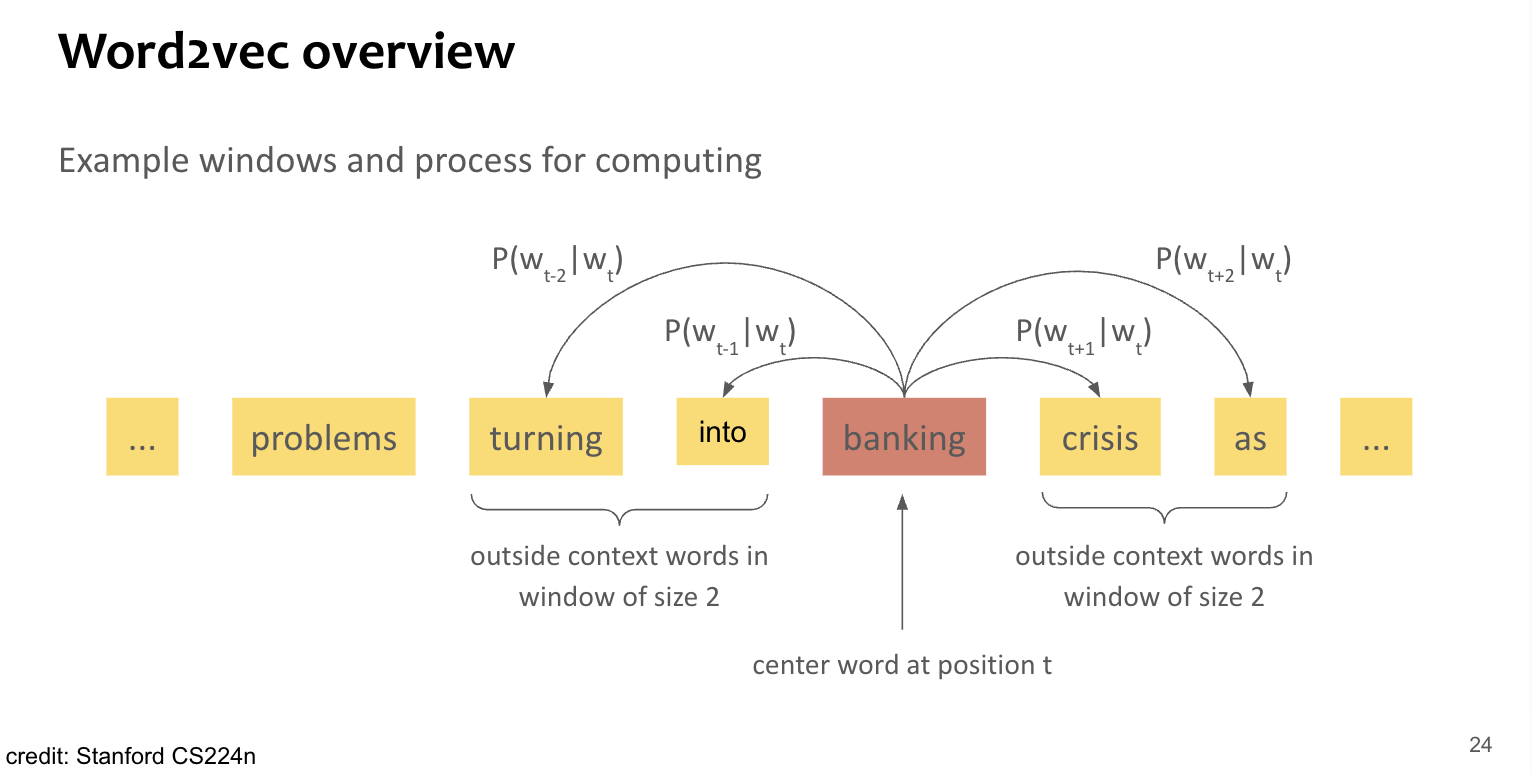
Optimization target 즉, parameter는 모든 단어들의 vector embedding 자체. → voca size 만큼의 d-dimensional vector x 2(center version, context version)
즉, θ∈R2dV
where d: vector dimension, V: voca size
Question
Why 2 vectors?
easy to optimize.
average both at the end.
Summary
위 식을 통해 gradient를 계산해보면, ∂vc∂log∑w=1Vexp(uwTvc)exp(uoTvc)
Check
위에 건 v에 대한 미분. u에 대한 미분도 해볼 것.
Tip
Negative sampling이 training에 도움을 준다. (efficient vs naive softmax)
Model Variants(Type)
Skip-grams(SG)
predict context by using center.
course cover this .
Continuous Bag of Words(CBOW)
predict center by using context.
Negative Sampling
Summary
위 식 중 확률 P(o∣c)는 아래처럼 softmax항으로 생겼는데, P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
denominator에서 sum term이 voca size라 연산량이 크다.
따라서 naive하게 softmax를 사용하지 않고, negative sampling을 사용한다.
Important
Main Idea: train binary logistic regression for a true pair(center word and a word in its context window) vs several “noise” pairs (the center word paired with a random word)
Quote
From “Distributed Representations of Words and Phrases and their Compositionality” (Mikolov et al. 2013)
Word2Vec 같이 iterative하게 구한 값들 말고, 예를 들어 전체 corpus에서 단어 빈도 등을 사용할 수 있지 않냐.(더 traditional 한 approach)
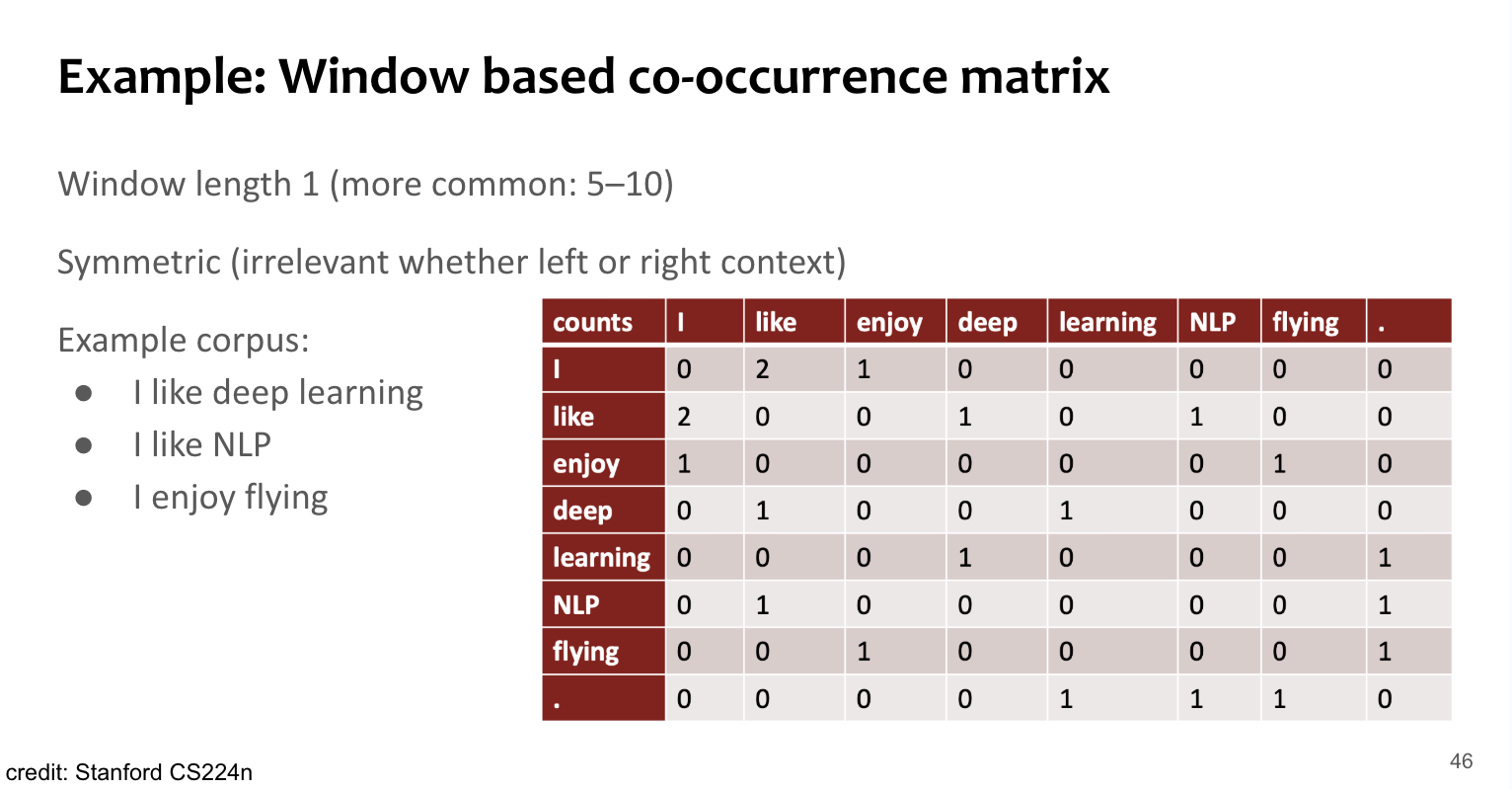
Building a co-occurrence matrix X : 2 options: windows vs. full document
Window: Similar to word2vec, use window around each word → captures some syntactic and semantic information (“word space”)
Word-document co-occurrence matrix will give general topics (all sports terms will have similar entries) leading to “Latent Semantic Analysis” (“document space”)
Example
Co-occurence Vectors
NOTE
Simple count co-occurrence vectors
Vectors increase in size with vocabulary
M = (voca_size, voca_size)
Very high dimensional: require a lot of storage (though sparse)
Subsequent classification models have sparsity issues → Models are less robust
Low-dimensional vectors
Idea: store “most” of the important information in a fixed, small number of dimensions → a dense vector
Usually 25–1000 dimensions, similar to word2vec
How to reduce the dimensionality?
SVD(SIngular Value Decomposition) 하면 되긴 하는데 여전히 expensive.
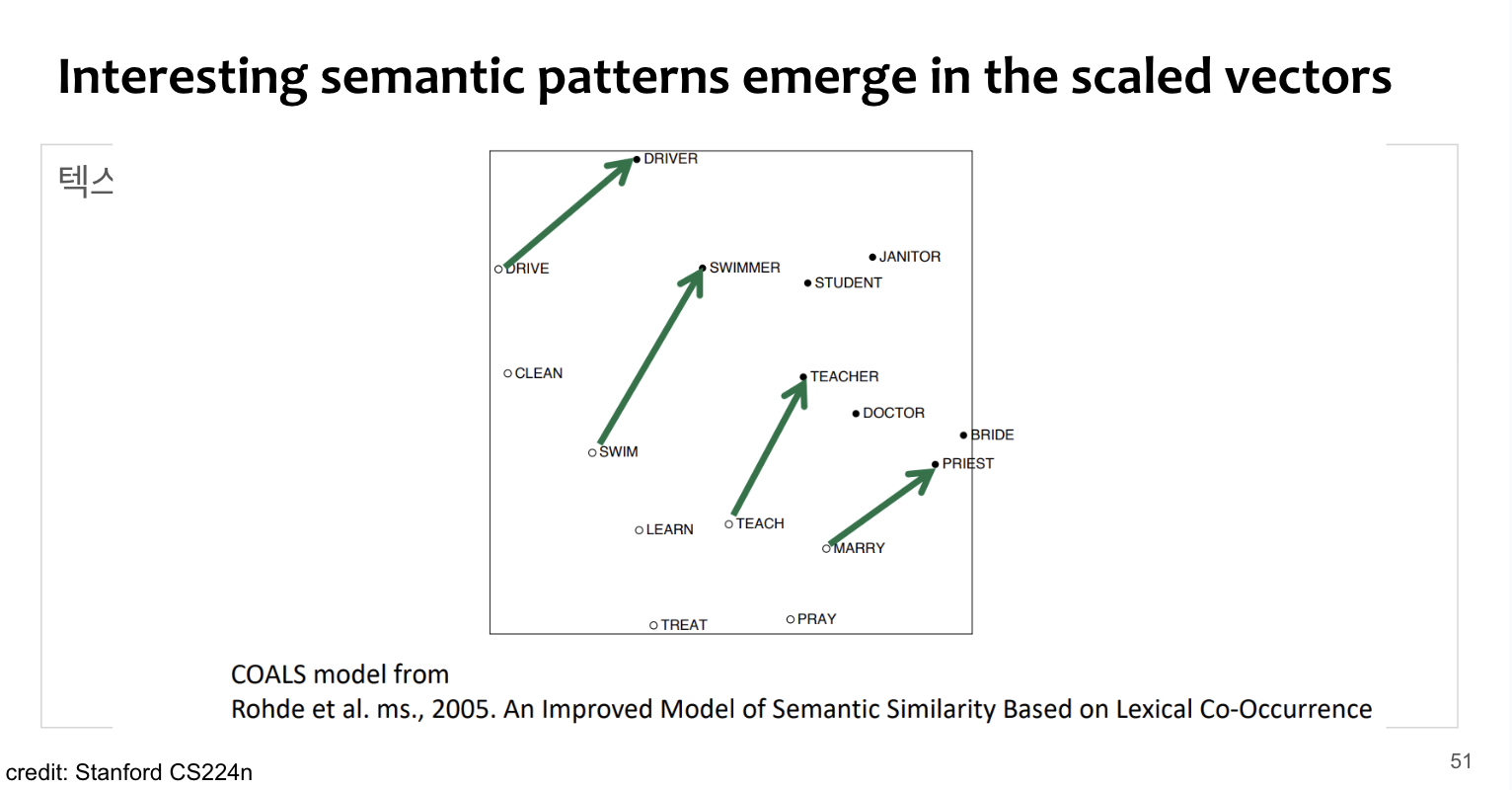
Example
raw 값 그대로 SVD하면 별로 좋지 못한 결과. 따라서 아래 tip
Tip
Check
GloVe
GloVe
Summary
“Count-based의 전역 정보 + Word2Vec의 학습적 효율성을 결합한 모델”
Count-based vs Direct prediction
Multi column
Count based LSA, HAL (Lund & Burgess),COALS, Hellinger-PCA (Rohde et al, Lebret & Collobert)
Fast training
Efficient usage of statistics
Primarily used to capture word similarity
Disproportionate importance given to large counts
Direct Prediction Skip-gram/CBOW (Mikolov et al)NNLM, HLBL, RNN (Bengio et al; Collobert & Weston; Huang et al; Mnih & Hinton)
Scales with corpus size
Inefficient usage of statistics
Generate improved performance on other tasks
Can capture complex patterns beyond word similarity
Important
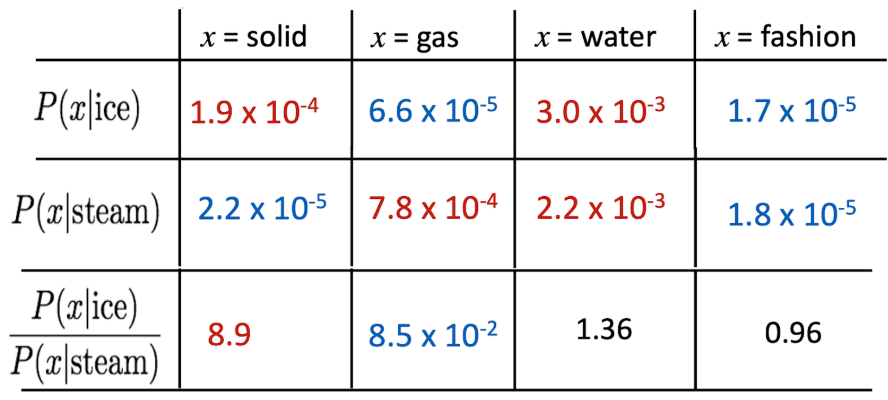
“Crucial insight: Ratios of co-occurrence probabilities can encode meaning components”
x=solid 를 보면, ice랑 더 관련 있음. 이러한 확률 비를 vector space에 모델링 하는 것이 GloVe
위의 걸 어떻게 Design?
Q: How can we capture ratios of co-occurrence probabilities as linear meaning components in a word vector space (i.e., embedding ratios of co-occurrence probabilities)?
A: Log-bilinear model wi⋅wj=logP(i∣j)
with vector differencs wx⋅(wa−wb)=logP(x∣b)P(x∣a)
GloVe
Summary
count base, direct prediction을 합치니,
fast training
scalable to huge copora
good performance even with small corpus and small vectors
word embedding이 좋은지 아닌지 어떻게 알 수 있나? → related to evaluation in NLP
Intrinsic:
Evaluation on a specific/intermediate subtask
Fast to compute
Helps to understand that system
Not clear if really helpful unless correlation to real task is established
Extrinsic:
Evaluation on a real task
Can take a long time to compute accuracy
Unclear if the subsystem is the problem or its interaction or other subsystems
If replacing exactly one subsystem with another improves accuracy ⇒ Winning!
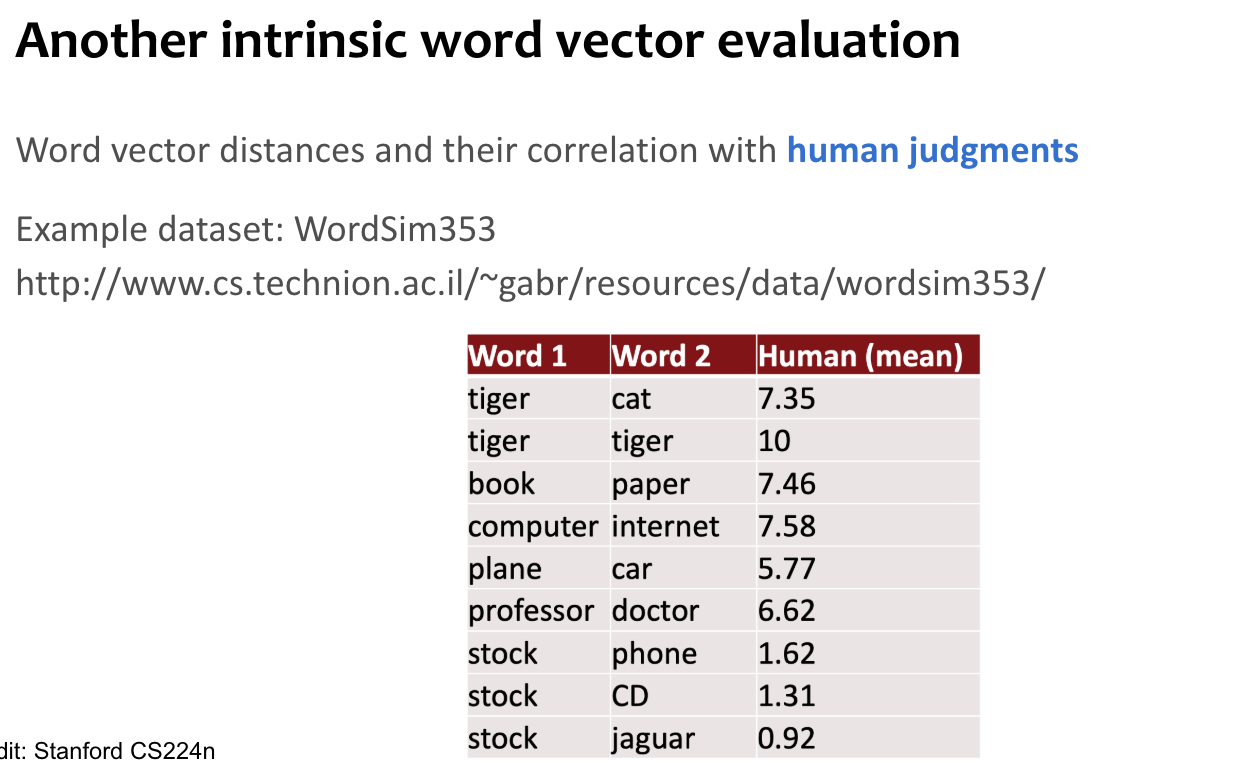
Intrinsic Evaluation
Example
In word vector, man : woman = king : ?
Warning
information 간 관계가 non-linear하다면?
Example
Extrinsic Evaluation
Word Senses
Summary
하나의 word라도 의미가 매우 다양하다.
이전 시도들은 모두 하나의 단어에는 하나의 fixed된 word embedding을 부여하니 이걸론 모자르다.
Example
multi-sense 문제를 cover하기 위해 Improving Word Representations Via Global Context And Multiple Word Prototypes(Huang et al. 2012) 논문에서는 아래처럼 bank라는 단어에 여러 개 embedding을 부여한다.
알고리즘 흐름 (요약) by GPT
1단계: 기본 임베딩 학습
일반 Word2Vec으로 초기 임베딩 생성.
2단계: 문맥 벡터 수집 및 클러스터링
각 단어 주변 window 벡터(=context mean vector)를 모아서 클러스터링.
3단계: Sense assignment
각 등장 단어를 해당 문맥의 클러스터에 따라 sense ID 부여 (예: bank₁, bank₂).
4단계: 재학습
sense-tagged 코퍼스로 다시 Word2Vec 학습 → multi-sense embeddings 생성.
이후 Neelakantan et al., 2014 (Multi-Sense Skip-gram) 모델로 확장된다고 함.