DL의 목표는 데이터를 통해 데이터를 잘 설명하는 함수(parameter)를 찾는 것. Backpropagation 의 과정을 살펴보면, analytic한 해를 구하는 방법보다는 numerical approach가 현재의 mainstream.
따라서 optimization 분야도 challenging 한 분야.
Optimization Challenges
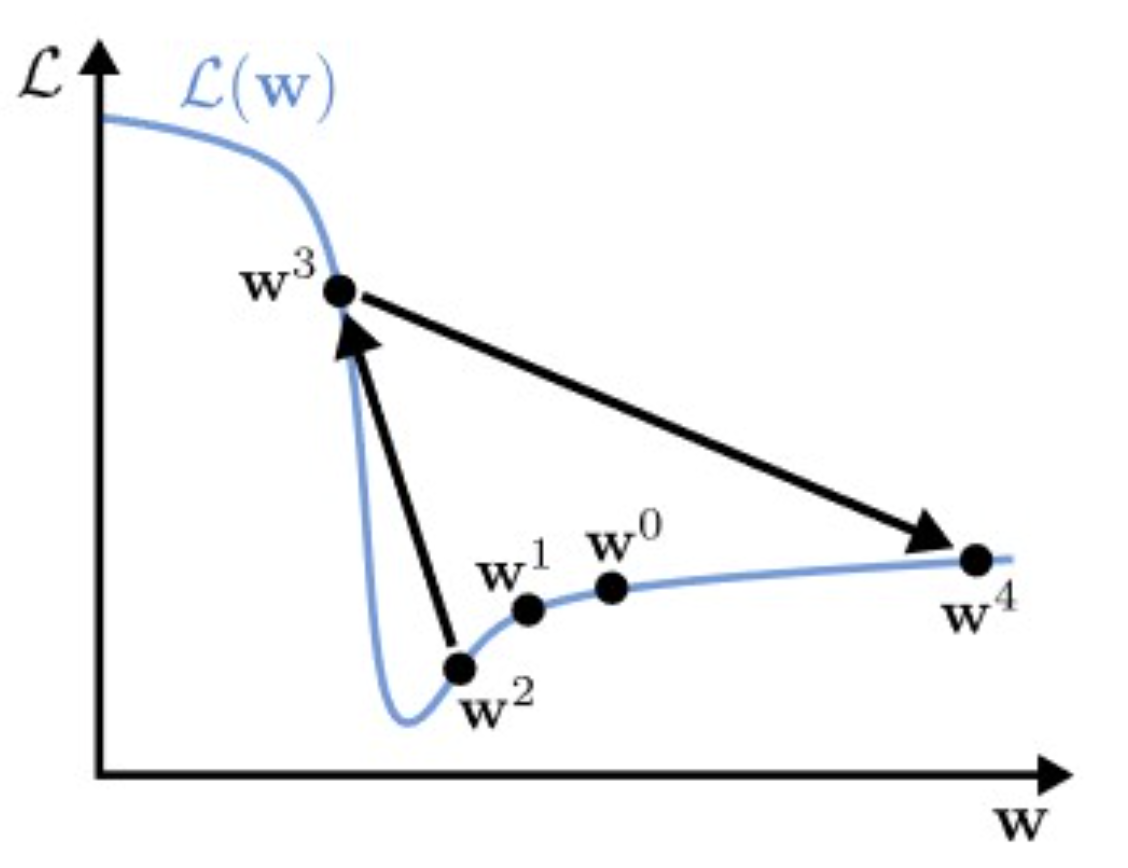
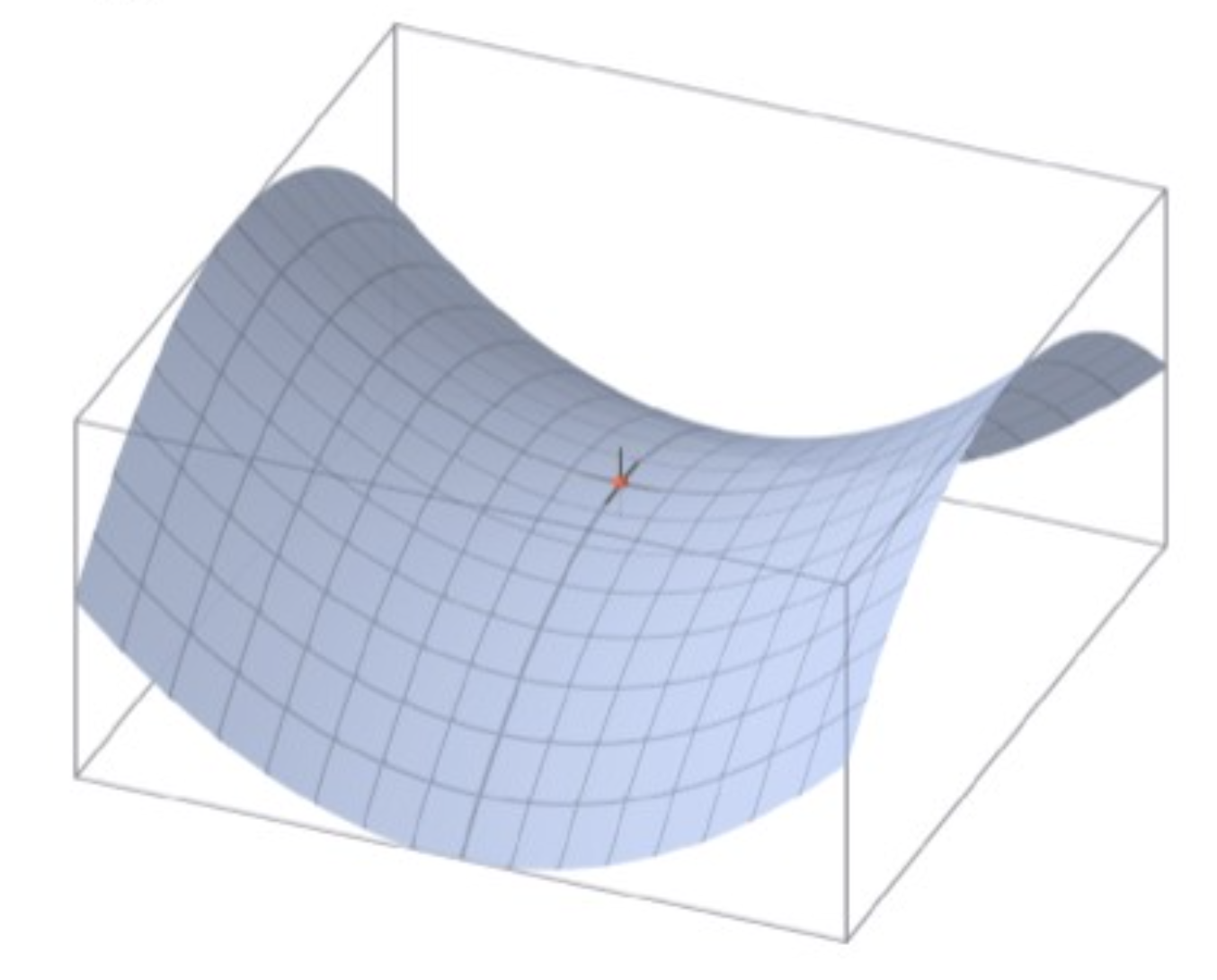
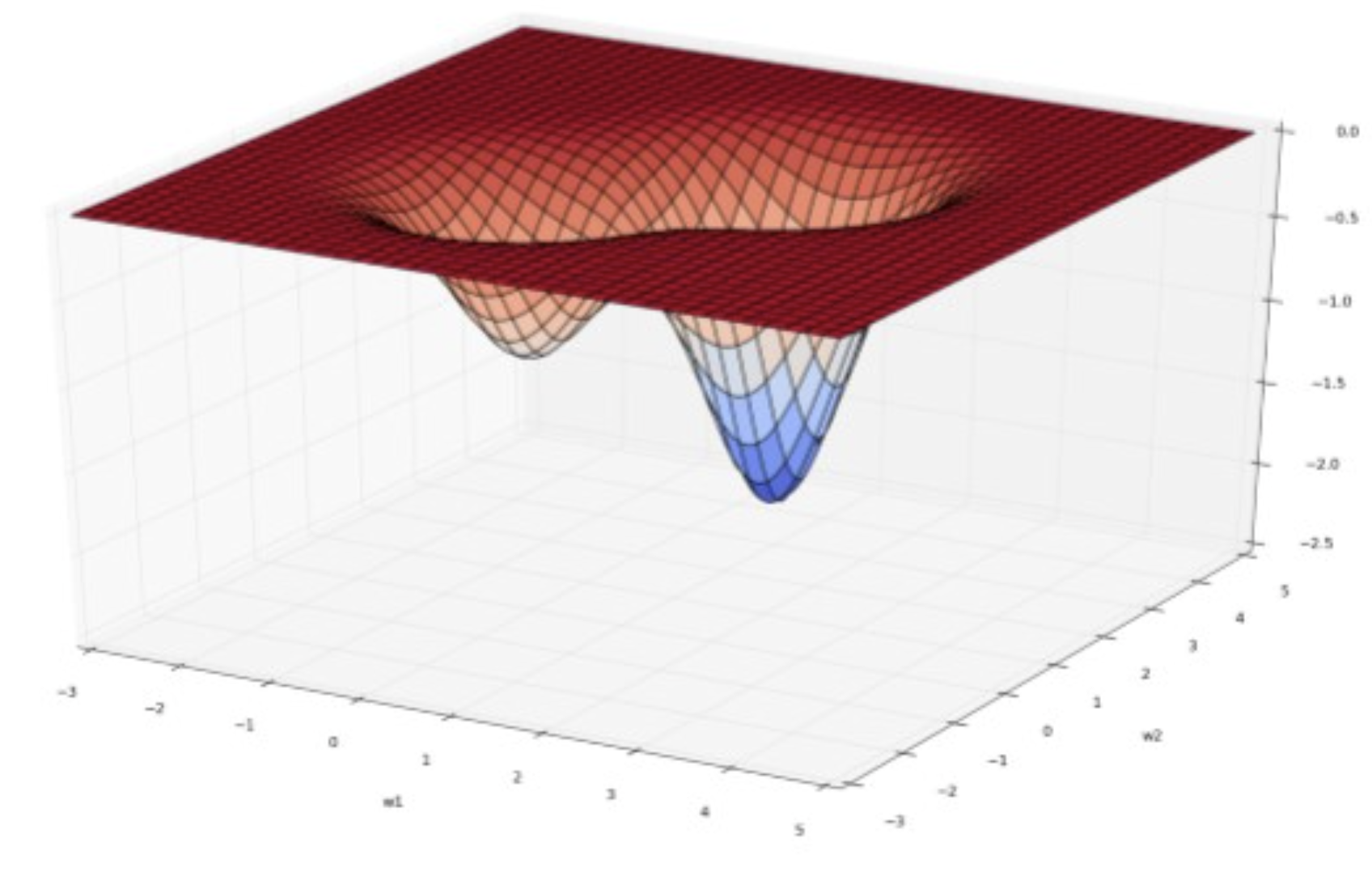
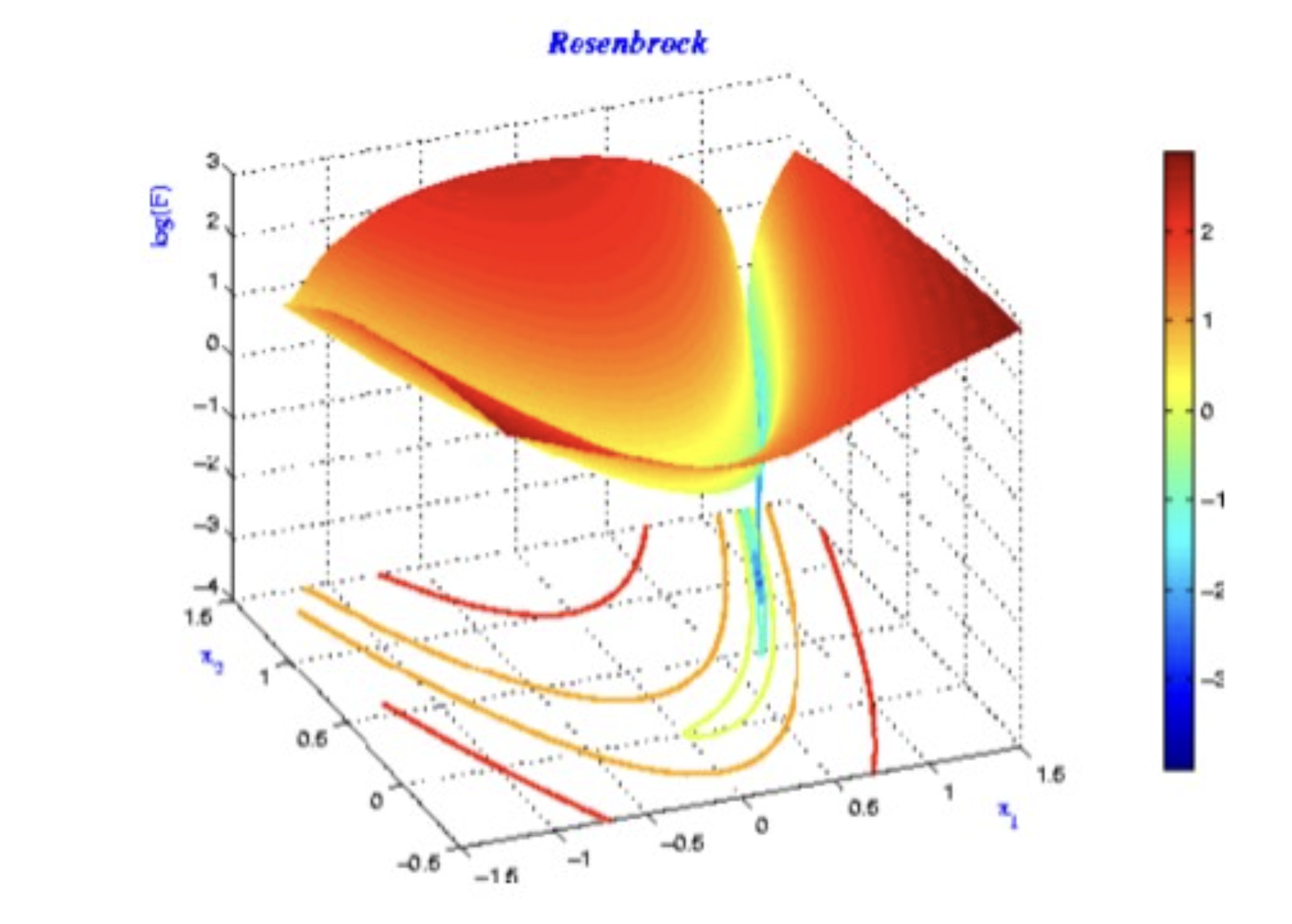
NN은 기본적으로 파라미터의 단위가 매우 크기 때문에 loss L(w) 이 일반적으로 non-convex.
multiple local minima가 존재하지만, optimization으로 얻은 solution은 그중 하나.
ex) we can permute all hidden units in a layer and get the same solutions.
Good point! : 일반적으로 지금까지는 많은 Local minima들이 만족할 만한 성능을 보여주어서 문제가 심각하게 되지는 않고 있다.
Gradient Descent(GD)
Gradient Descent
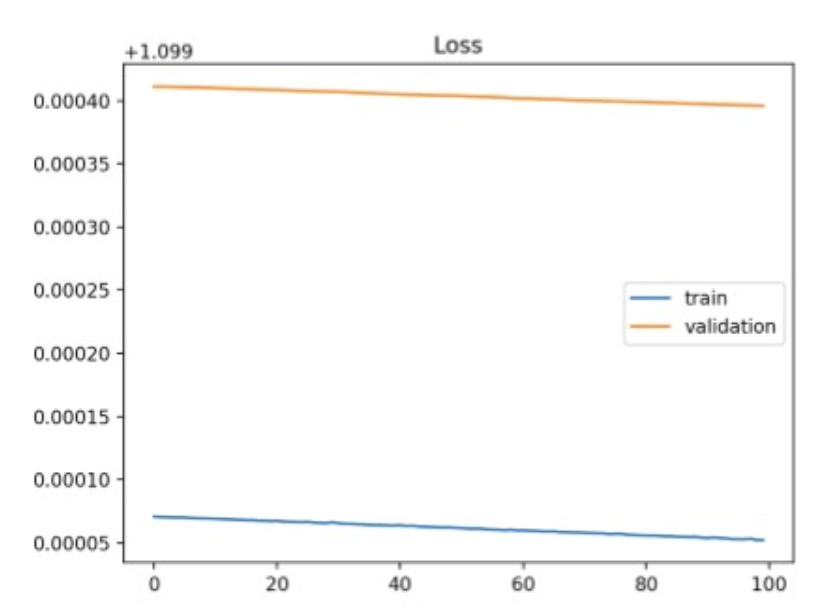
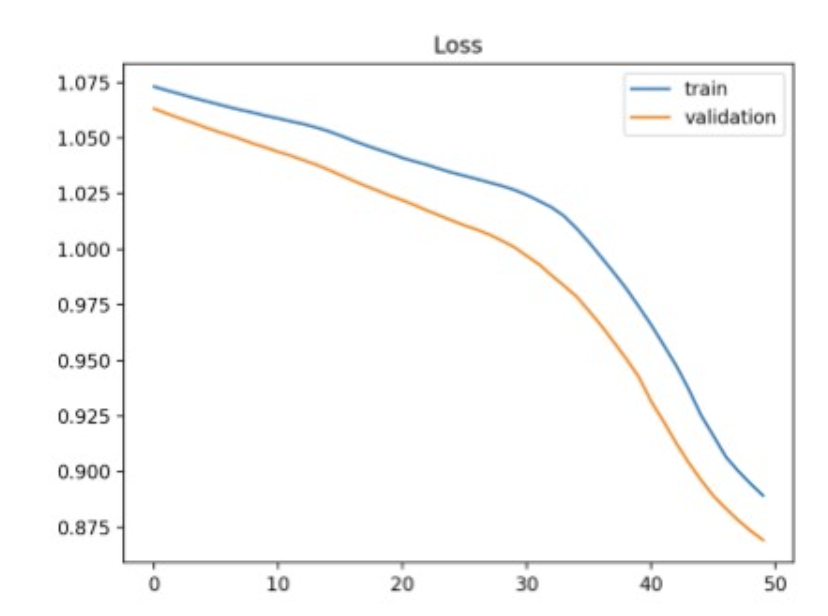
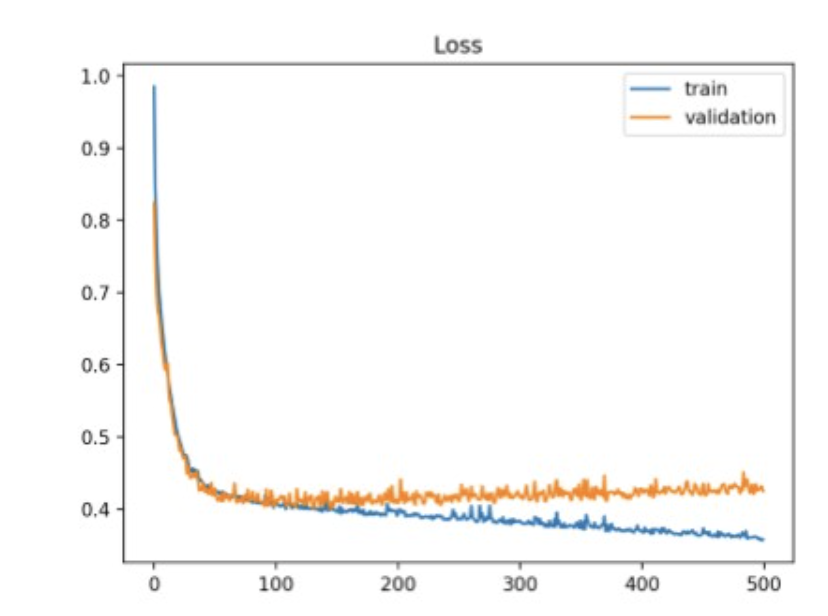
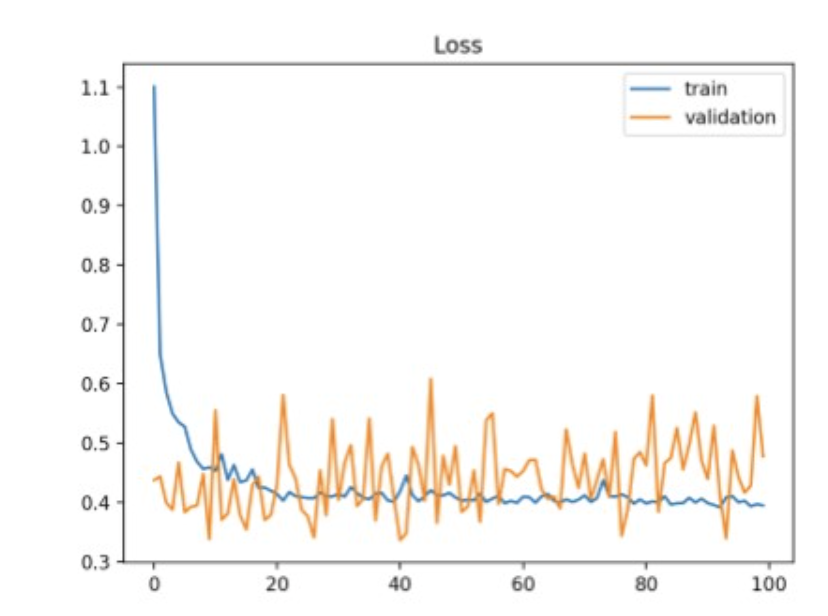
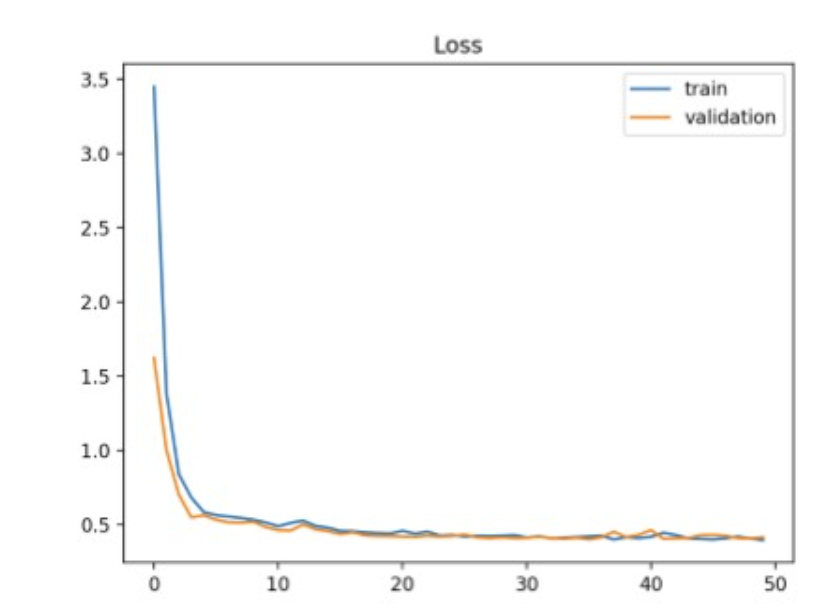
Gradient를 이용해서 loss landscape의 minima point 를 찾아가는 기술.
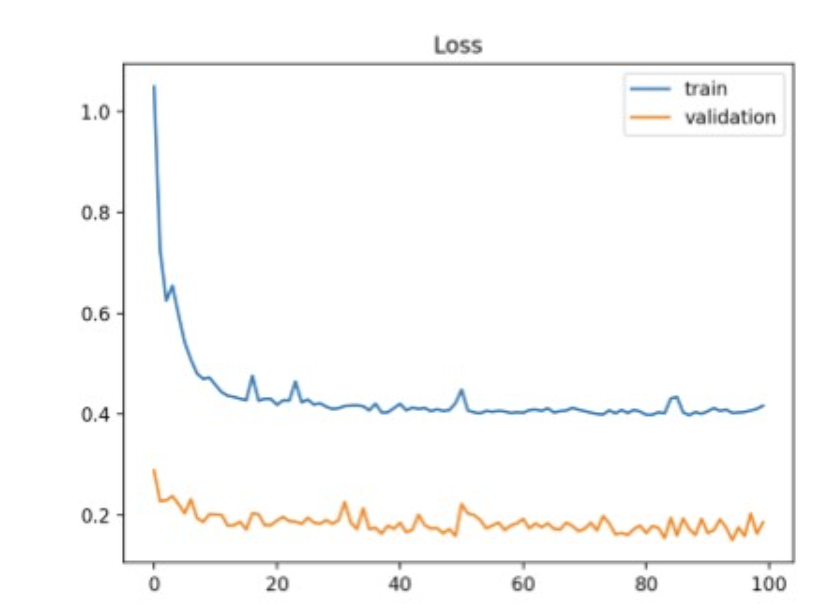
Training loss는 계속 줄지만, validation loss은 낮아지지 않음.
train을 계속하면, 모델은 train-set에만 잘 작동하는 함수로 fitting되니,
generalization이 떨어지고, validation-set 또는 unseen-data에 대해서도 loss가 커짐.
Help
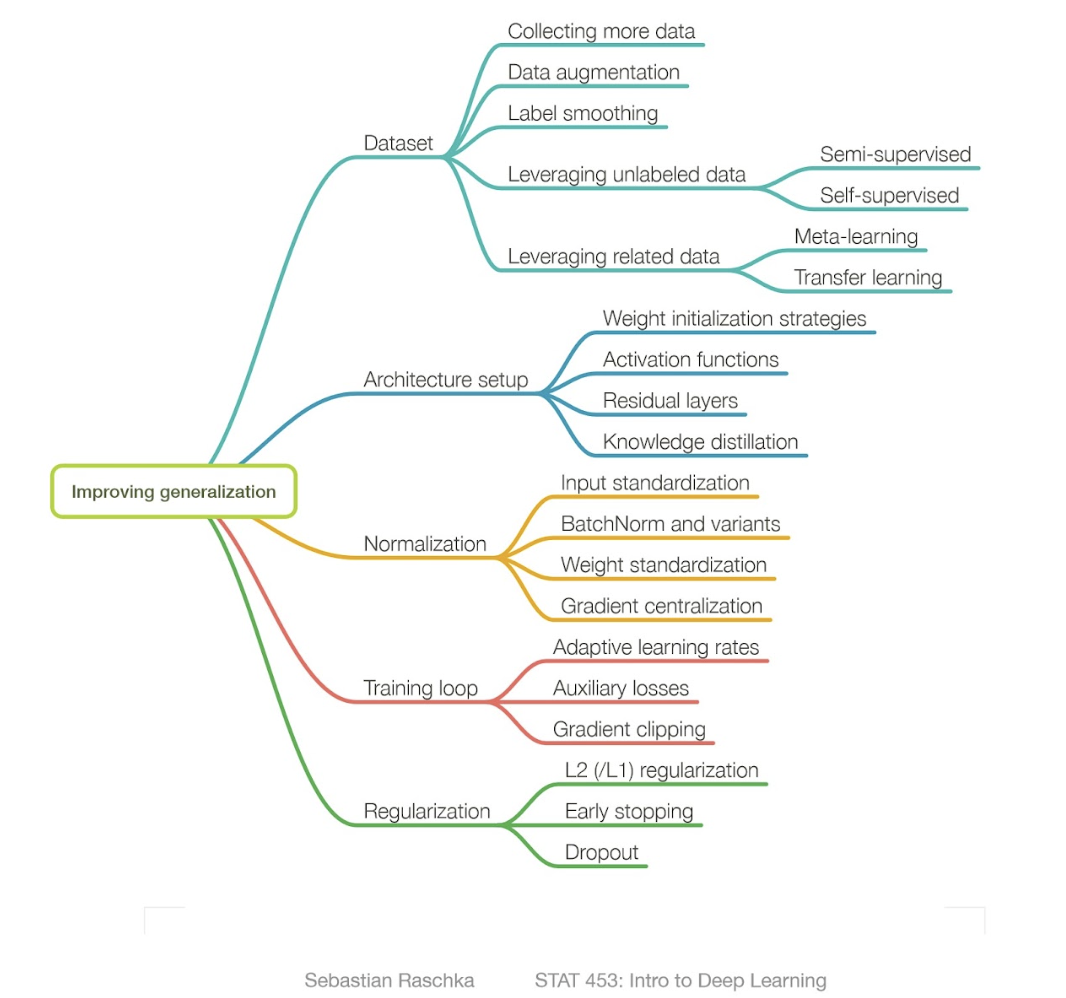
To solve the problem, several methods are recommended.
Get more data: 사실상 이게 best. 그러나 cost-issue.
모델한테 패턴을 학습할 기회를 더 주는 것.
Data Augmentation : 데이터를 더 collecting 하는 것 보단 현실적.
train-set의 diversity를 주는 것.
Better Data: low-quality data를 remove.
Transfer Learning: task-suit 하게 준비된 set으로 fine-tune.
Simplify model: 모델의 capacity가 충분해서 train-set의 너무 과한 패턴을 학습한 거니, 모델의 복잡성을 줄여서 generalization performance 확보.
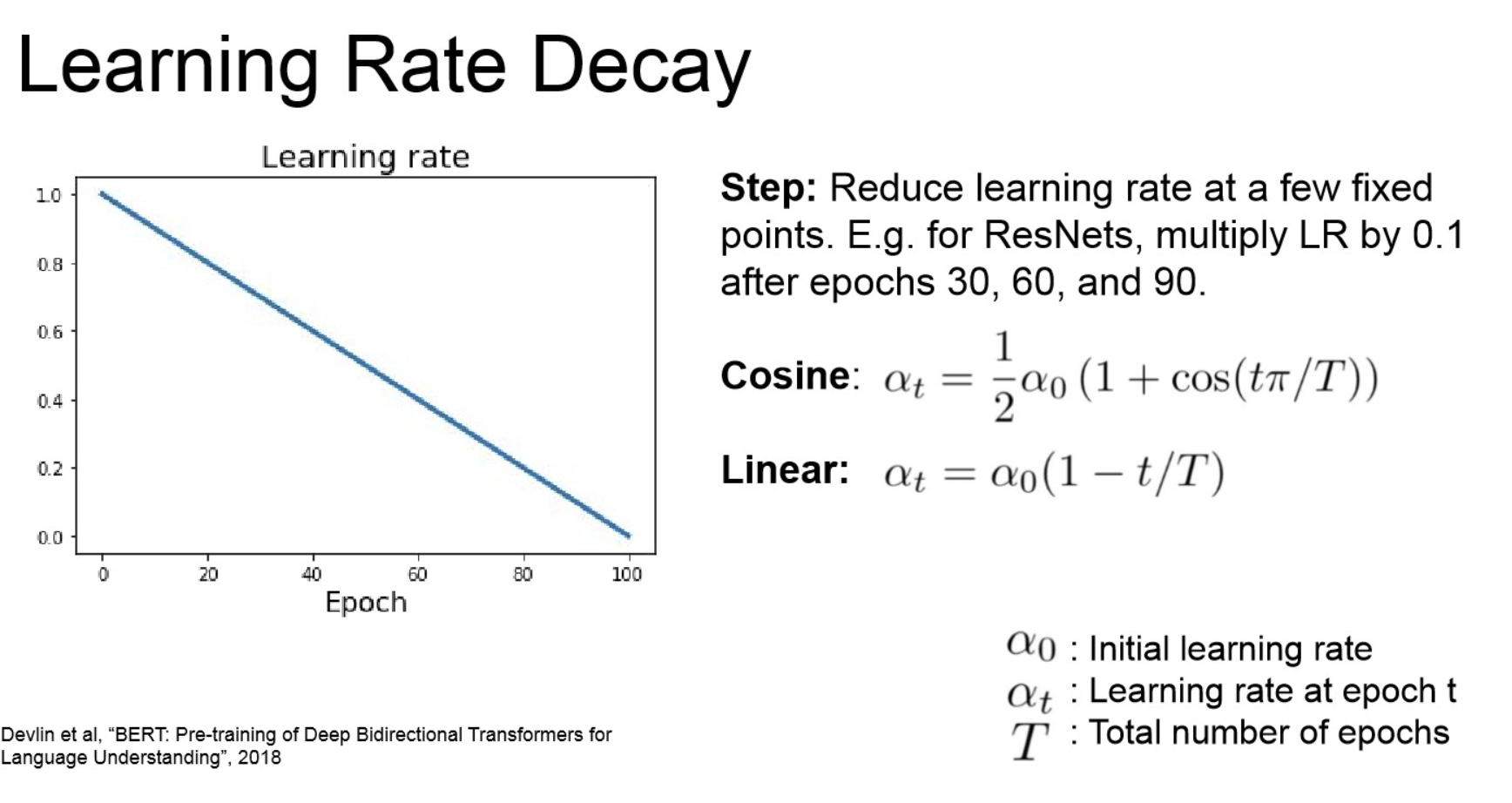
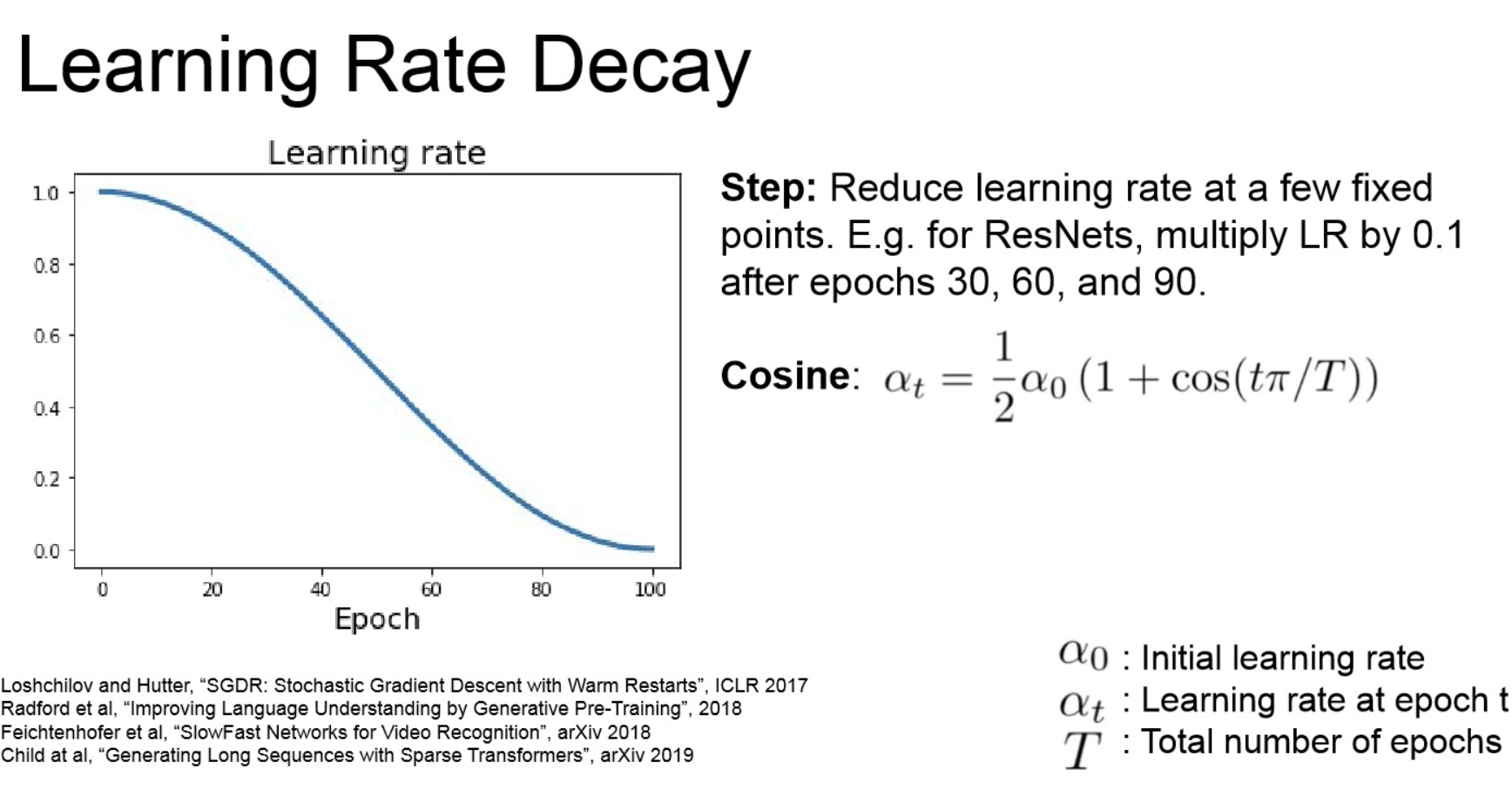
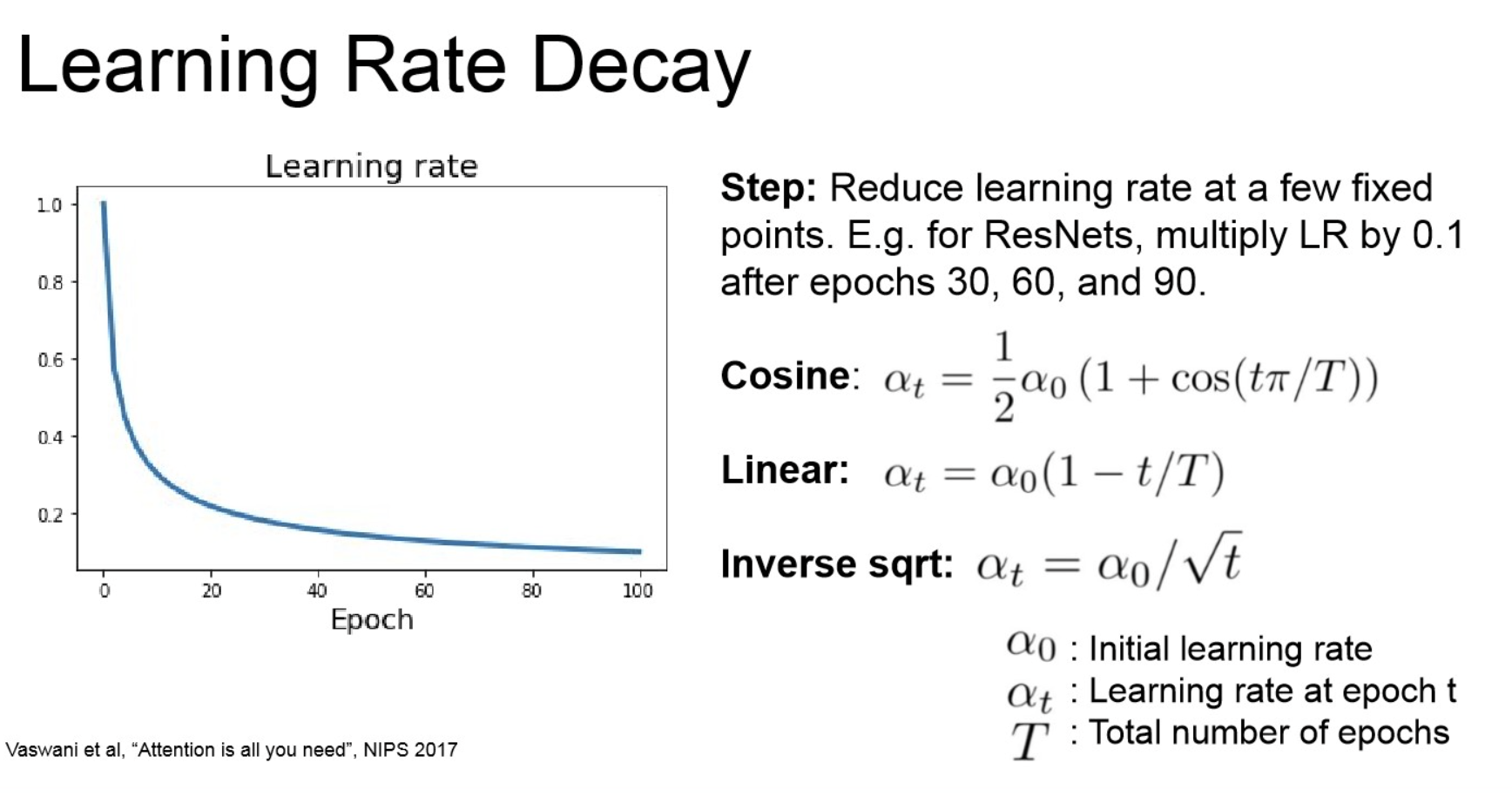
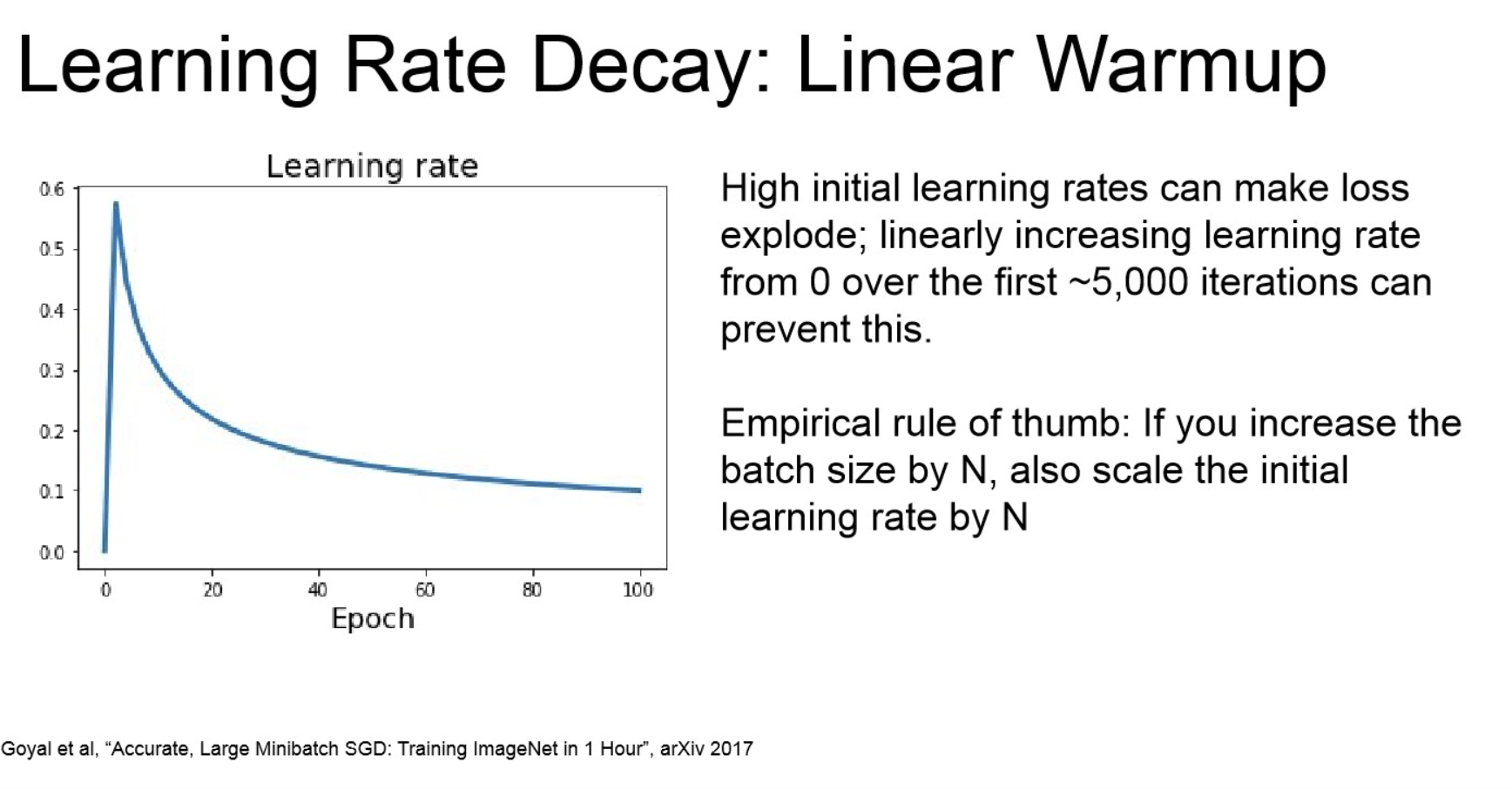
Learning Rate decay: fine-tune은 학습 후반에서 미세한 gradient에서 학습하는 거니, decaying은 후반에서 이러한 것들을 완화해줌.
결국 가장 중요한 건, generalization performance.
Unseen Data에 대해 얼마나 날 predict할 수 있는냐가 핵심.
위는 그를 위한 strategies.
Dataset refinement
Data Augmentation
Summary
사실 best approach는 당연히 data를 더 collecting하는 것. 그러나, 현실적으로 어려우니,
그 대안으로 original train set에 적당한 transformation을 가해 train set으로 사용하는 접근.
Goal : “fake” data를 기존에 존재하는 데이터로부터 생성. → train-set으로 활용.
Note! : new data는 반드시 semantic 을 그대로 가져가야 한다.
DNN must be invariant to a wide variety of input variatiions
Often large intra-class variation in terms of pose, appearance, lightening, etc.
같은 고양이더라도, 여러 포즈가 있을 수도 있고,
Tips! : translation 같은 simple한 transform도 generalization performance를 꽤 올려준다.
Typical Examples
Image Crop
Affine Transform
Gaussian Blur
Gaussian Noise
Cutout
Contrast
Clouds
Random Combination
Tips for modeling
Tip
2개의 NN 비교 시, 동일한 augmentation을 사용하도록.
Data Augmentation 역시 network design의 일부로 취급함.
“It is important to specify the right distribution(often done empirically).”
ensemable idea 적용해서,
training time에는 random crop/scales + train 한 번
inference time에는 avg predictions for a fixed set of crops of the test image.
AutoAugment 는 Reinforcement Learning방법을 사용하여 strategy를 알아서 찾게 한다.
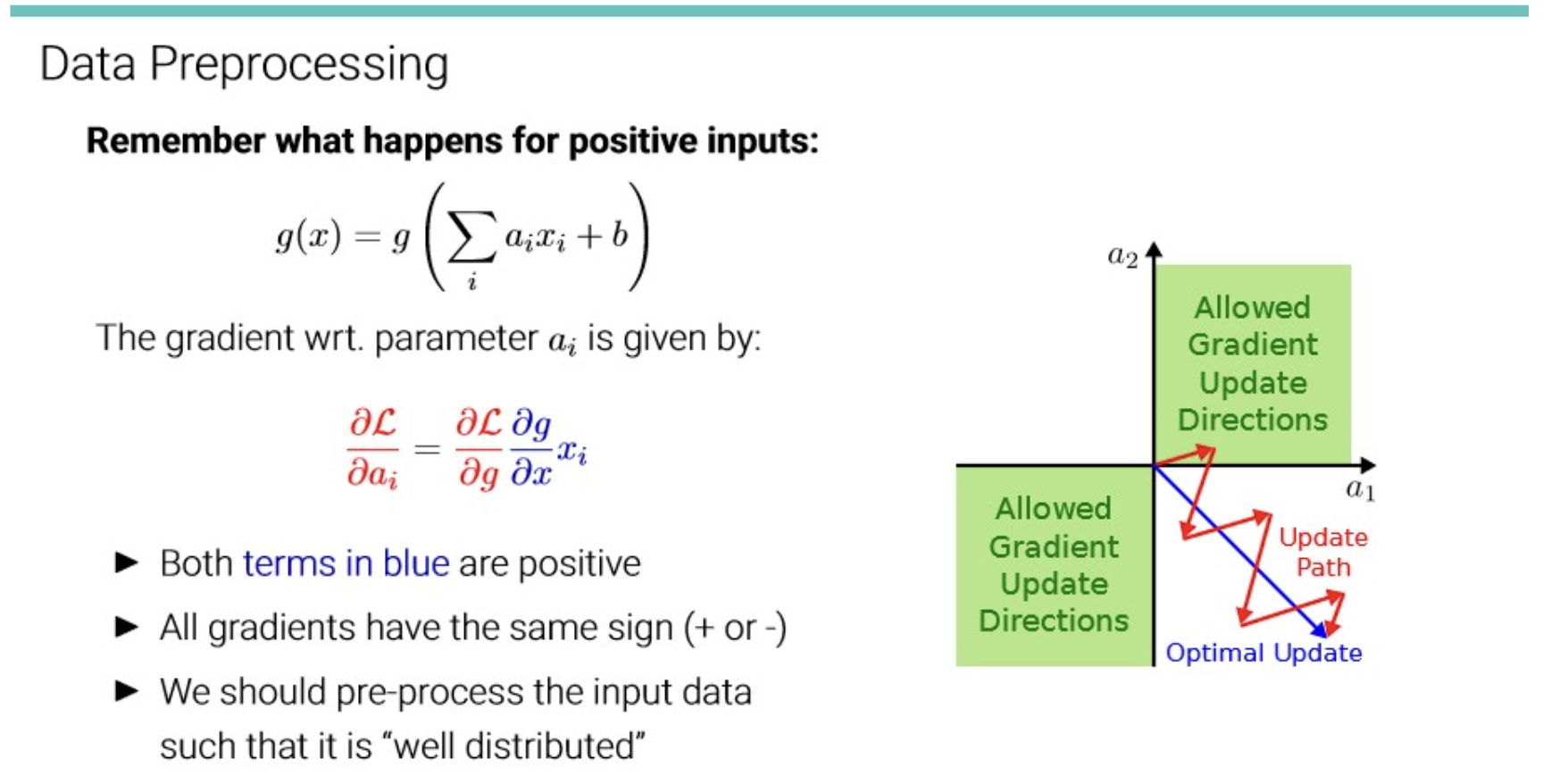
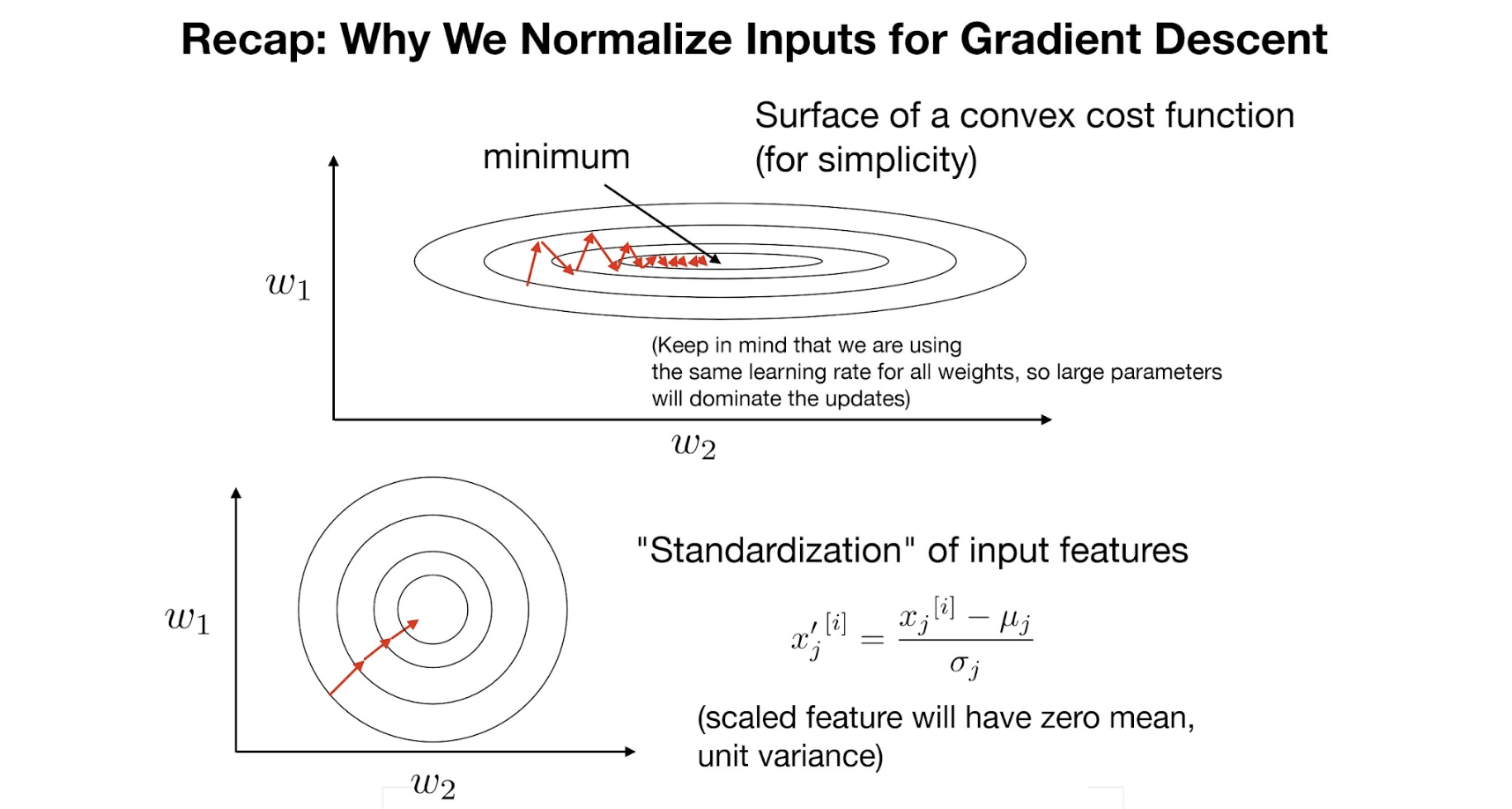
이전에 본 듯이, input data의 distribution이 고르게 분포하지 않을 경우,
gradient 가 fluctuate될 수 있다. → inefficient
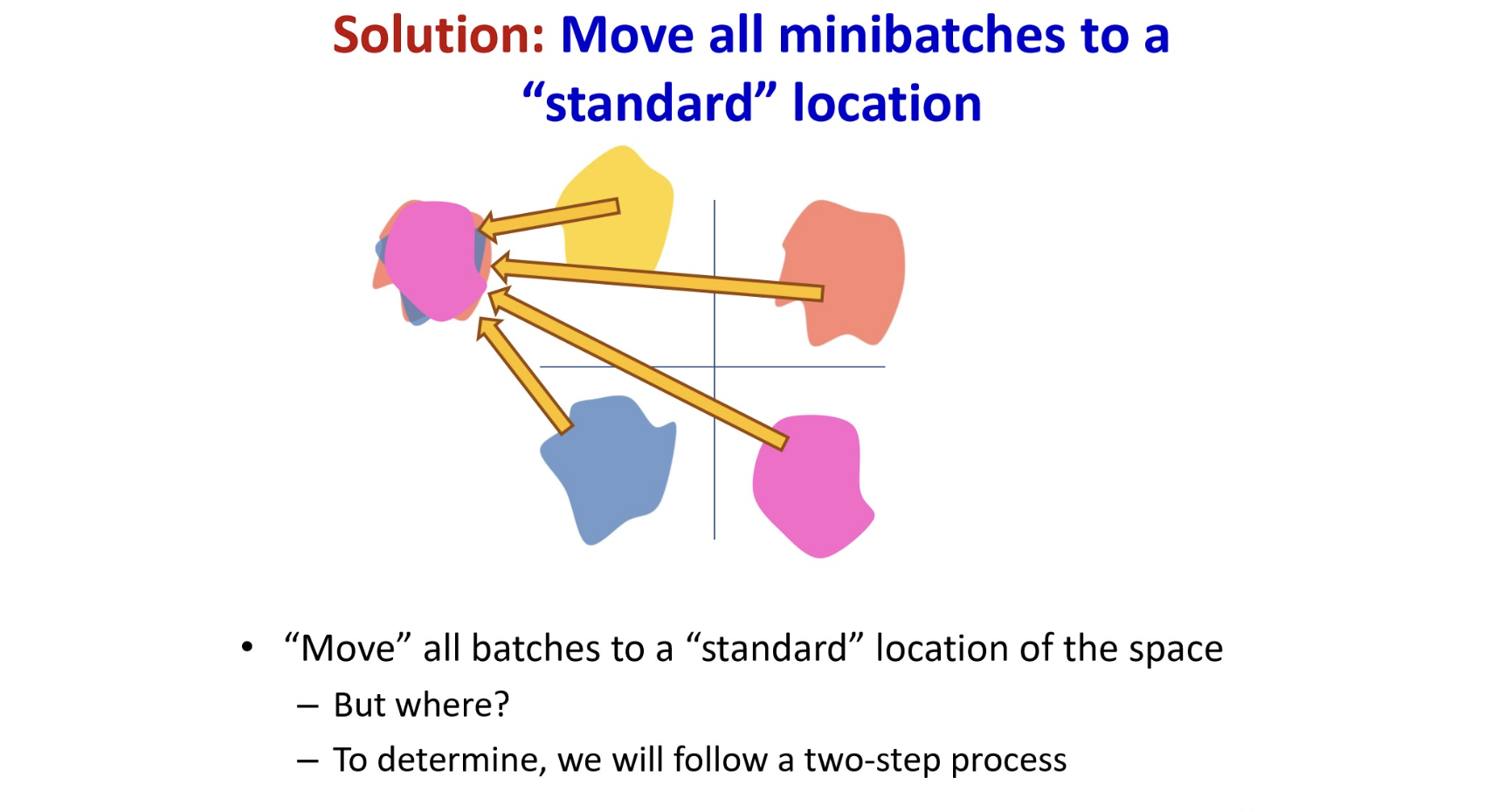
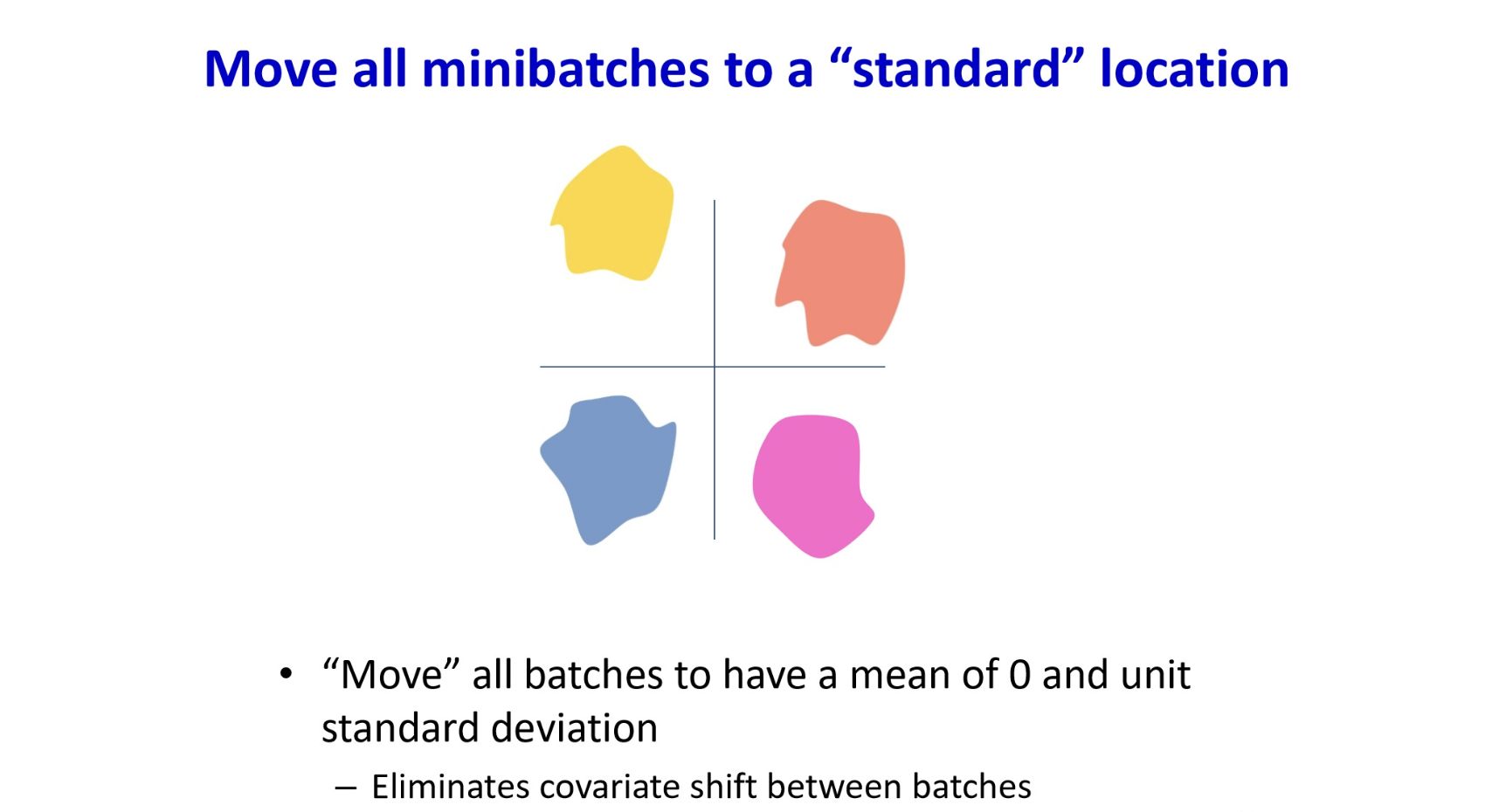
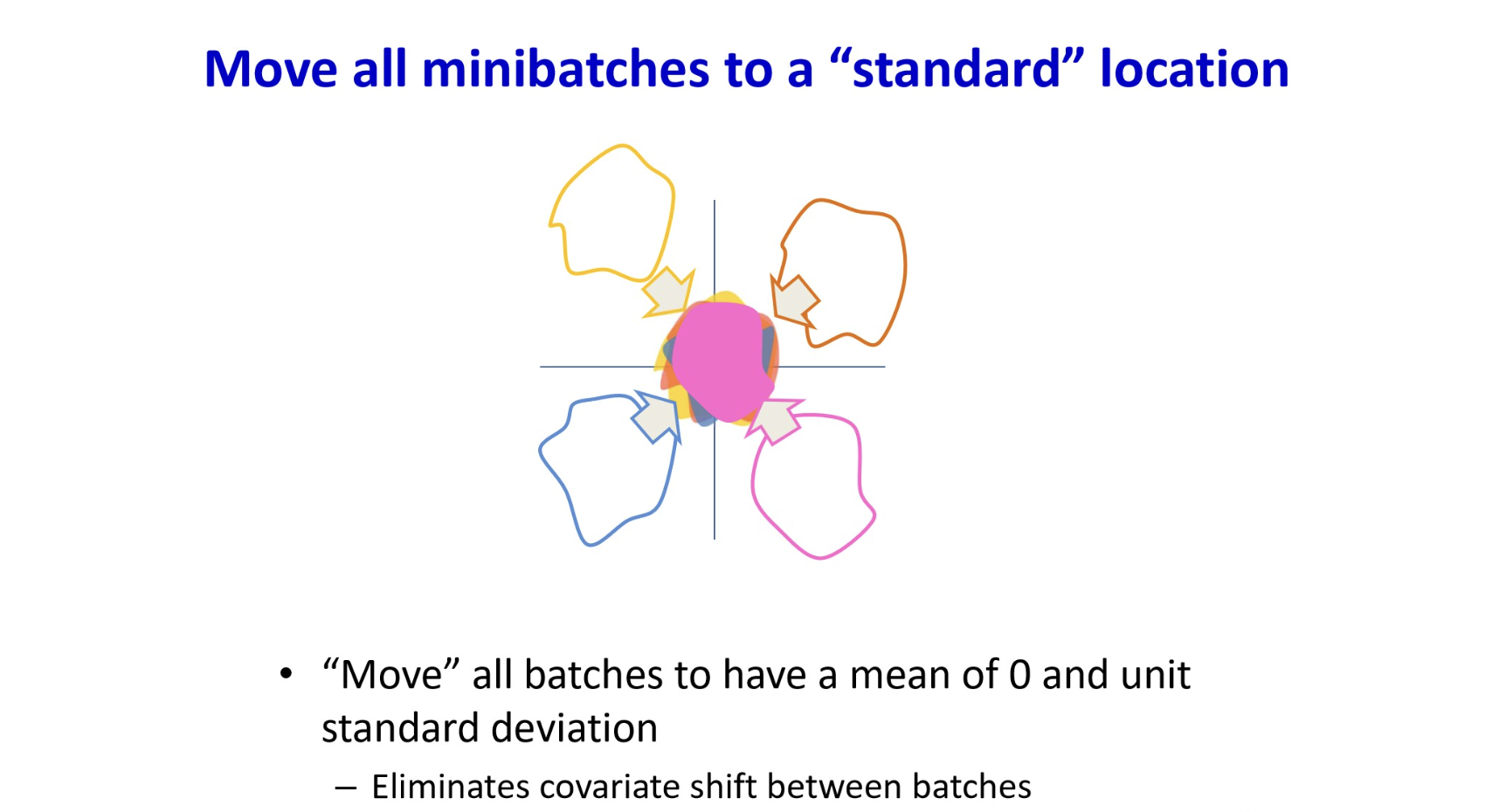
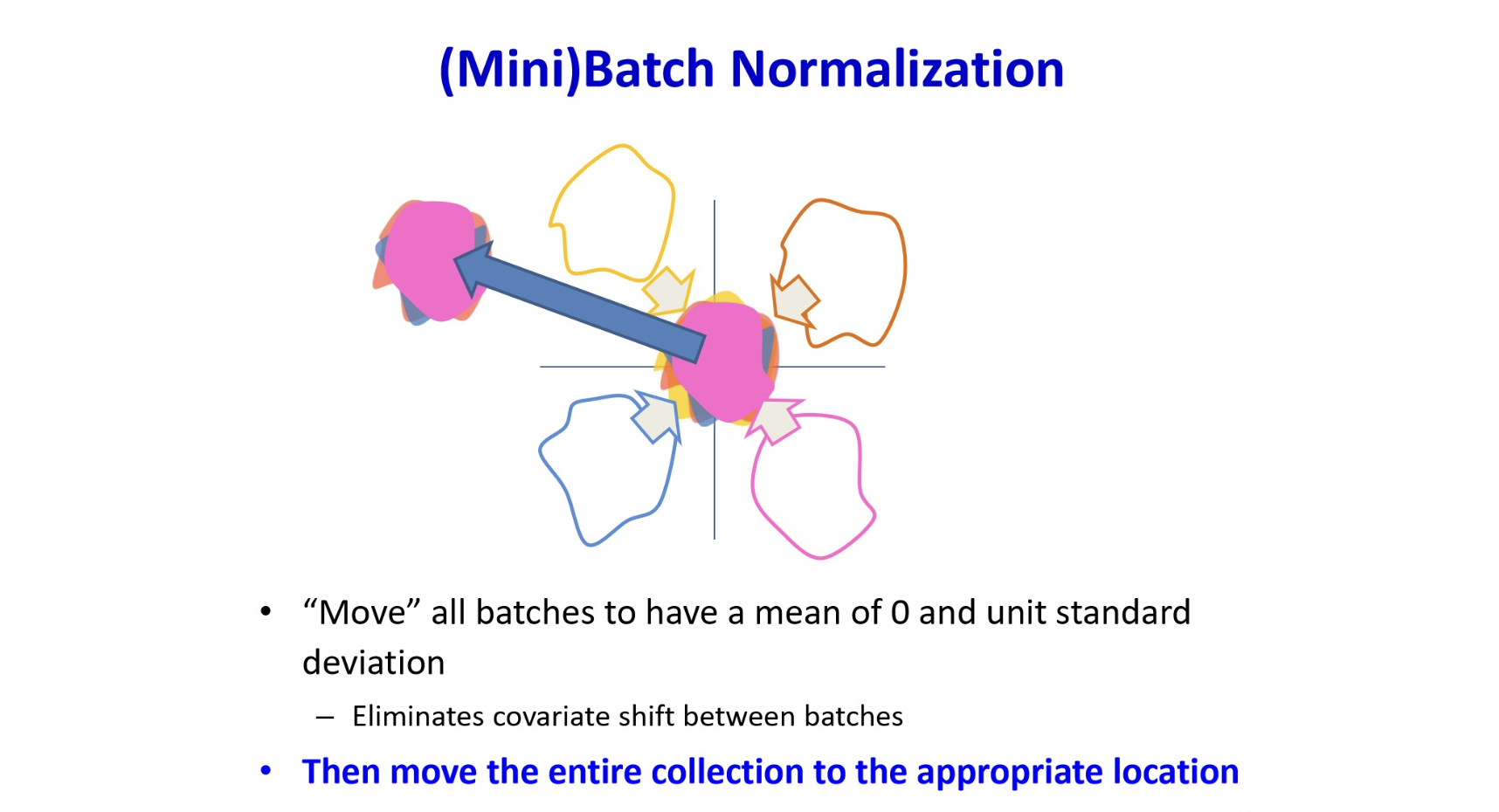
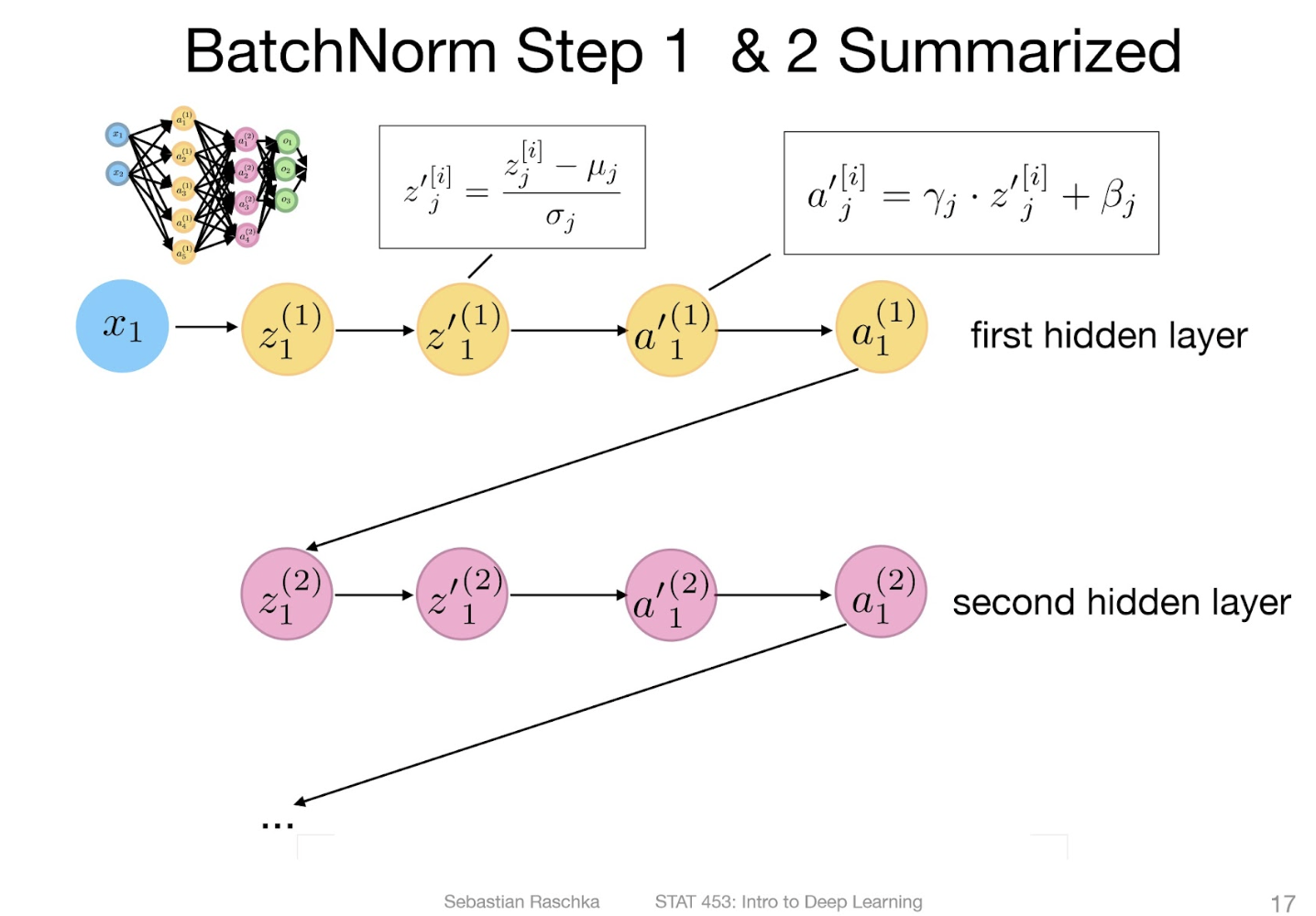
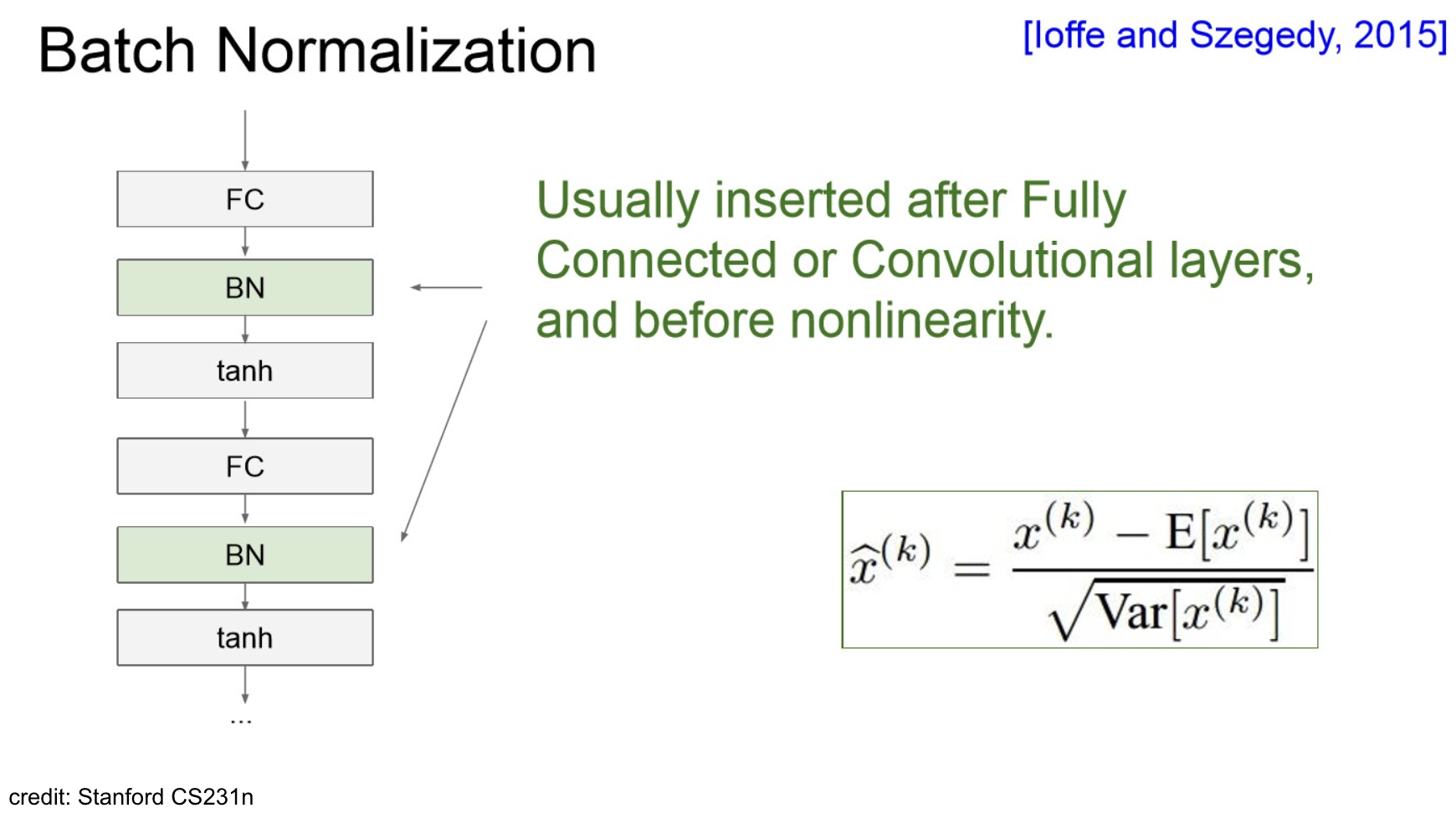
The problem of covariate shifts
Training 과정에서 우리는 일반적으로 데이터셋이 비슷한 분포에서 나왔다고 가정하는데,
mini-batch 로 학습하는 경우에는 이 단위가 mini-batch에도 적용된다.
그러나, 그렇지 않을수도 있다. (전체 데이터가 한 번에 모델에 입력되어 iteration하는게 아니니까.)
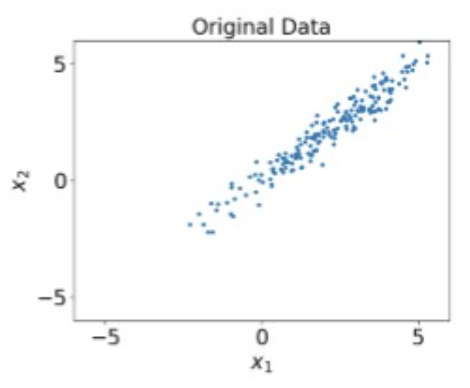
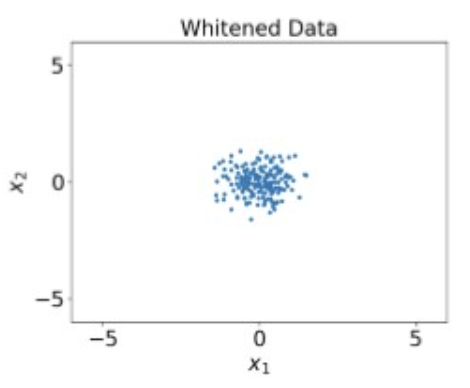
Data preprocessing Example
Original Data
Multi column
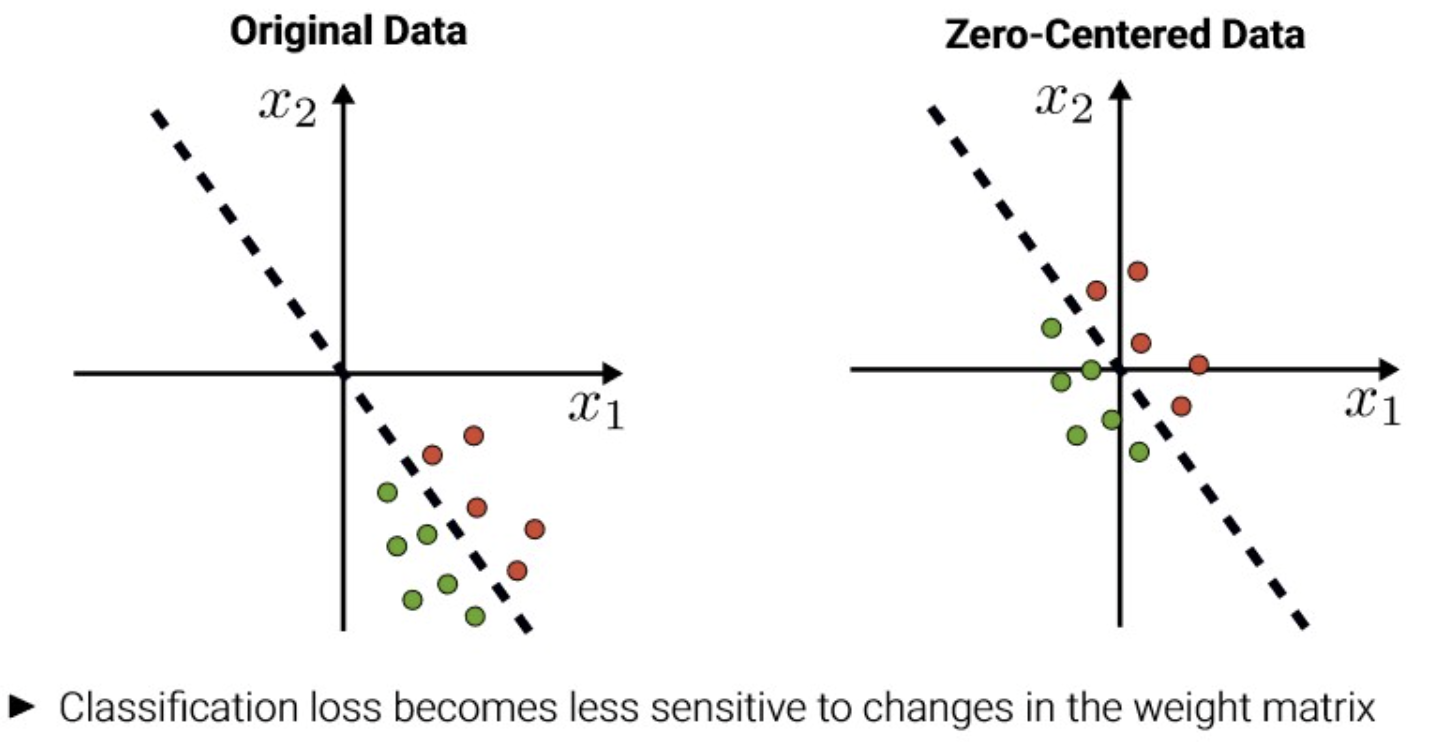
Zero-centered xi,j←xi,j−μj
with μj=N1∑i=1Nxi,j
Normalized xi,j←xi,j/σj
with σj2=N1∑i=1N(xi,j−μj)2
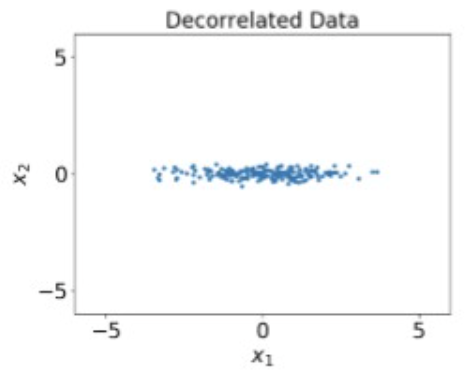
Decorrelateed
Multiply with eigenvectors of covariance matrix
Whitened
Divide by sqrt of eigenvalues of covariance matrix
divergence
원본 링크with
with
/../../../AI/Concepts/assets/GD-w-small-lr.png)








.png)